2.3 GPU并行计算架构
对于习惯于针对CPU进行串行编程的程序员来讲,图形处理器(Graphics Processing Unit,GPU)总是透着一层神秘的面纱,甚至对于很多程序员,他们会认为针对GPU编程学习的难度要远远大于CPU。这种印象或者体验源于GPU编程的一些特征,例如针对CPU的串行编程符合人类的逻辑思维特征,而针对GPU的编程更多的是以并行编程为主;同时串行编程模型已经非常成熟,在这种模型下,处理器将一些并行特征隐藏在硬件级别,使编译器能够对并行编程进行高度抽象,所以程序员不需要去了解处理器架构的一些知识,然而针对GPU的并行编程仍然依赖于程序员对硬件知识有一定的了解(例如GPU使用受程序员托管的内存模型,而不是完全基于硬件托管的内存模型,还有数据的对齐以及内存合并等概念),才能够充分提高并行计算的效率;另外,GPU并没有独立的编程模型,它通常是和CPU一起形成一个非对等的多处理器架构,开发者需要通过CPU来调度和管理GPU设备,内存,以及管理这些设备内的各种状态等等。
虽然本书的内容主要只是涉及GPU图形渲染管线的运用,而并不是更广义上的GPU并行编程,然而理解图形处理器架构对于真正的图形程序开发者仍然是必不可少的知识,它有助于我们更深刻地理解图形接口以及更好地运用它们。所以本节�将会详细讨论GPU架构相关的各种知识,带着这些知识,我们将会在下一章更好地理解图形渲染管线。需要注意的是,本章的内容主要围绕Nvidia的GPU处理器产品进行介绍,然而大多数现代图形处理器的架构是相似的。
为什么需要另外一个并行计算架构
为了更好地理解GPU架构,本节不会直接给出GPU的架构,然后讲述其对应的功能,而是选择首先讲述它的来由,通过对这些客观条件的理解,能够帮助我们更好地理解GPU架构。
由前面的内容可知,多处理器架构完全能够支持并行计算,例如它将相同的程序发送至多个处理器或线程执行,并分别赋予相应的处理数据,为了支持更大的并行性,我们可以使用更多的处理器。那么这样做存在的问题是什么?
使用一般的多处理器架构来执行大规模并行计算的限制正来源于针对串行计算优化的缓存系统,由于处理器时钟和主内存读取速度之间的巨大差异导致数据读取的巨大延迟,缓存系统通过充分利用局部性原理预取指令或数据,大大减少了对数据读取导致延迟的不必要的等待,以保证串行程序的高效执行。然而,高速缓存系统的成本非常高,并且占据芯片很大的空间,操作数从主内存到ALU之间的传输需要耗费大量的电能,这些因素使得基于缓存的处理器系统很难扩张以应付大规模的并行计算。相反,从设计处理器过程的成本来讲,计算单元ALU则是很便宜的,它们能够以很高的速度运行,消耗很小的电能并占据很少的物理硅片空间。
所以,很明显的问题是,为了满足大规模并行计算,我们需要一些新的思路来取代缓存系统的功能及作用,理解这个新系统的特点及机制是理解GPU架构的关键。
内存结构
GPU架构和CPU的最大不同在内存系统上,CPU为了最大限度地减少程序员对内存的关心,使用一种称为硬件托管的内存模型,在这种模型中,缓存系统自动根据局部性特征获取当前正在执行指令附近的指令以及当前正在处理数据附近的数据,并在指令将计算结果写入到寄存器之后自动将其写入到缓存系统,以及更新多处理器架构中其他处理器的缓存。所有这些操作都是硬件自动完成的,程序员完全不需要关心其中的过程。
然而我们已经知道缓存系统的成本非常高,以至于不适用于大规模的并行计算,在大规模并行计算中,程序要处理的数据集的大小通常要数倍于一般的串行程序,我们根本不可能通过扩展缓存系统来满足大规模计算的需求,那样将导致巨大的成本。并且并行程序通常有数千个线程同时运行,大多数线程之间都是独立的,如果每个线程的中间计算结果都需要写回缓存甚至主内存,这也将是一笔巨大的浪费。
所以,GPU使用的是一种称为程序托管的内存模型,即数据的存放地点由程序员决定,因此它要求程序员需要对GPU内存结构有一定的了解。然而,由于GPU硬件不包含自动完成数据替换的逻辑,因此它也可以减少一部分芯片的面积以及能耗以容纳更多的计算单元。
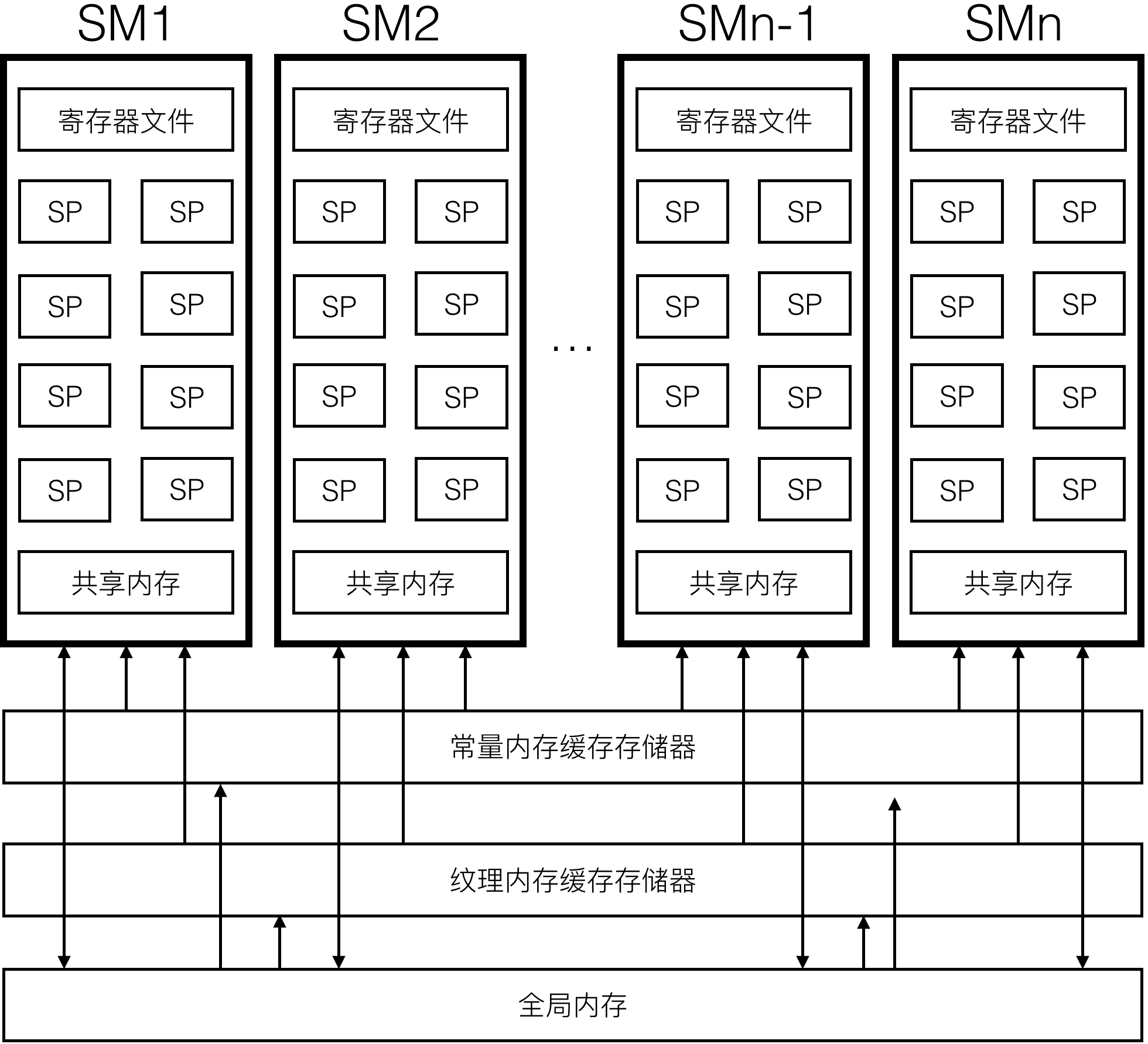
图(1):NVIDIA系列GPU的内存结构,它包含寄存器,共享内存,常量/纹理内存以及全局内存。与CPU的基于硬件的缓存模型不同的是,GPU使用的是基于程序托管的内存模型,即数据的存放位置可以由程序来控制
图(1)表示的是一个GPU内的内存结构,其中流处理器族(Stream multiprocessor,SM)相当于一个CPU核,每个SM内部有多个流处理器(Stream processor,SP),每个SP用于执行并行计算中的一个独立的线程,我们将在后面详细讲述这些概念。GPU中的内存分为4种:寄存器,共享内存,常量/纹理内存以及全局内存,每种存储类型的带宽和延迟是不同的,如表(1)所示。
| 存储类型|寄存器|共享内存|纹理/常量内存|全局内存 |
| 带|约8TB/s|约1.5TB/s|约200MB/s|约200MB/s| | 延迟|1个周期|1-32个周期|400-600个周期|400-600个周期|
表(1): GPU中不同存储类型的带宽和延迟时间
全局内存
图形处理器又称为加速卡,它是计算机系统的一种附属设备,它不能独立运行,必须借助于CPU才能发挥作用。所以通常一个GPU应用程序包含一个CPU宿主程序,以及一些GPU内核函数,当程序运行时,宿主程序将这些GPU内核函数指令及相关的数据分发到GPU设备上计算,然后从GPU内存中取回计算结果。
GPU拥有自己独立的内存,所以宿主程序需要将数据从CPU传输到GPU以进行计算。通常GPU设备都是通过PCI-E(Peripheral Communications Interconnect Express)总线与处理器相连,如图(2)所示,目前PCI-E 3.0的传输速率为8GB/s。PCI-E是全双工总线,这意味着数据的传入和传出可以同时进行并享有同样的速率,也就是说我们在以8GB/s的速度向GPU卡传送数据的同时,还能够以8GB/s的速度从GPU卡接受数据(然而实际上数据在CPU和GPU内存之间的传输还会经历一些低速的前端总线,所以实际上并不能达到8GB/s这么高的速率。不过Nvidia在其最新的Pascal处理器架构[cite a:PascalArchitectureWhitepaper]中使用了一种新的直连技术Nvlink,它可以使GPU之间通过Nvlink而不是PCI-E连接,其可以提高GPU-GPU之间高达160GB/s的传输速度。如果处理器本身支持Nvlink技术(例如IBM的POWER8处理器),其还可以提供相同的CPU-GPU之间的传输速度。)。然而,这并不意味着如果不接受数据,我们就可以以16GB/s的速度向GPU卡传送数据。

图(2):在一般的处理器架构中,GPU通过PCI-E总线与CPU联通
GPU中的主内存称为全局内存,这是因为GPU和CPU都可以对其进行写操作。宿主程序要想在GPU上执行计算,首先将CPU中的数据和指令通过PCI-E总线传输至GPU的全局内存中,接着GPU中的各个内核线程从全局内存中读取数据并执行计算,然后将计算结果写回到全局内存,最后宿主程序再从GPU全局内存中读取数据回CPU中。例如图形渲染管线中的顶点数组,纹理数据等,即是通过OpenGL等图形接口将CPU中的顶点数据传输到GPU全局内存中,只不过在图形接口中通常还会做一些数据的格式转换(例如归一化等)。
由于并行计算涉及巨大的数据集,这些数据从CPU到GPU全局内存之间的传输,以及全局内存到GPU内核函数的寄存器之间的传输都会产生大量的延迟,所以在GPU中可以使用一种比较高级的流传输的模型来使传输数据和内核函数的执行重叠进行,参见本章后面的内容。
全局内存是GPU中内核函数访问最�慢的内存,由于GPU架构使用程序托管的内存模型,所以内核函数可以选择不需要将每个变量的中间结果都写回到全局内存,这些中间数据可以保存在内核函数所在的执行单元本地,而等到内核函数执行完毕时才将本地的数据写回到全局内存,这大大节省了数据在全局内存和内核函数之间的不必要的传输时间;此外,一个线程束的线程对全局内存连续地址的访问还会涉及合并,这些内容将在本章后面描述。
常量/纹理内存
对于并行计算,每个线程使用的数据大都是相互独立的,例如对一个数组进行操作,每个线程分别读取数组中的一个元素进行相关的计算,线程通常不需要数组中除之外的元素数据。这样的数据可以直接存放在全局内存中,线程执行时内核函数直接(不经过缓存系统)向全局内存请求,如果相邻线程请求的数据地址是连续的,它们可以被合并使其只有一次内存请求,再结�合后面的延迟隐藏技术,可以提供比较高的计算效率。
然而,对于另外少量可以被多个线程随机访问的数据,并且多个线程可以访问同一个数据,这样的数据使用全局内存存储,然后直接被内核函数访问则效率不高。所以GPU提供另外一种内存结构用来存储这类可以被随机访问的数据。
常量以及纹理内存其实只是全局内存的一种虚拟地址形式,GPU并没有特殊保留的常量/纹理内存,但是常量/纹理内存能够提供高速缓存。此外常量内存和纹理内存都是只读内存。
如图(1)所示,常量内存可以被缓存到常量内存缓存存储器,而纹理内存可以被缓存到纹理内存缓存存储器,这些缓存存储器通常是L1级缓存,可以提供较全局内存更快的访问速度。然而由于所有缓存系统都是利用数据的局部性原理,所以它要求所有线程对数据的访问可以局部化到一个缓存的大小。例如一个64KB的常量大小以及一个8KB的常量缓存大小,这意味着可缓存的内存大小比为,如果能够将访问的数据包含或局部化到常量内存中一个8KB大小的块中,那么程序将获得很高的性能。否则,对于非均匀的常量内存访问,如果缓存没有命中所需的数据,将导致N次对全局内存的访问,�而不单是从常量缓存上获取数据。因此,对于那些数据不太集中或数据利用率不高的内存访问,尽量不要使用常量内存。
此外,对于纹理内存,它还提供基于硬件的线性插值功能。对于第一章讲述的纹理的放大和缩小操作,硬件会基于给定的纹理坐标值获取该纹素(texel)附近的多个纹素值,然后基于这些纹素值进行插值计算。对于一维数组来讲,它使用简单的线性插值,对于二维数组和三维数组,分别可以支持硬件级双线性插值和三线性插值。这样就使得渲染管线中的贴图可以高速处理。
纹理的另一个比较实用的特性是其可以根据数组索引自动处理边界条件,我们可以在数组边界按照环绕方式或夹取方式来对纹理数组进行处理。这一点非常有用,因为通常情况下它不需要通过嵌入特殊的边缘处理代码就可以对所有元素进行处理。而特殊情况下的代码处理通常会导致线程分支的产生,参见本章后面线程分支处理相关的内容。
共享缓存
由后面图形学处理器架构一节的内容可知,内核函数的多个线程会分配到多个SM上执行,据此我们可以对并行计算处理的数据进行一定的划分成多个处理子块,在每个子块内部的多个线程可以共享一些局部数据。如图(1)所示,这些单个SM内部的局部数据不需要通过缓慢的全局内存进行存储和读取,它们可以被存储在一个SM内部的共享内存当中。共享内存实际上是一个位于SM附近的L1高速缓存,它的延迟极低,大约有1.5TB/s的带宽,远远高于全局内存,但是它的速度大约只有寄存器的1/10。
为了提供更高的带宽,共享内存使用的是基�于存储器切换的架构(bank-switched architecture),它将共享内存平均分成多个相同尺寸的内存模块,称为存储体(banks),这些存储体内的内存可以被同时使用。任何对共享内存读或者写的操作可以均分到个不同的存储体地址,每个存储体地址都可以被同时访问,使其可以提供相对于单个内存模块倍的带宽。
例如费米架构的设备上有32个存储体,无论有多少个线程发起操作,每个存储体每个周期只执行一次操作,因此如果一个线程束(参见后面的内容)中的每个线程访问一个存储体,那么所有线程的操作都可以在一个周期内同时执行。此时无须顺序地访问,因为每个线程访问的存储体在共享内存中都是独立的,互不影响。如图(3)中上面的顺序访问,或者随机但是每个线程访问不同的存储体,这两种情况都可以同时执行。

图(3):共享内存被平均分配到32个存储体上,每个存储体在同一个周期内可以独同时被访问。上面的顺序访问(或者随机独立访问)可以被同时执行,然而下面多个线程读取同一个存储体将导致存储体冲突
此外,当线程束中所有线程同时访问相同地址的存储体时,会触发一个广播机制到线程束的每个线程,其他情况则将导致存储体冲突(bank conflicts),例如一个线程束中只有一部分多个线程访问同一个存储体则需要排队,此时当一个线程访问共享内存时,线程束中的其他线程将被阻塞闲置,并且此时并不会导致后面会讲述的延迟隐藏机制使处理器切换到其他线程执行。所以使用共享内存需要小心处理存储体冲突。
寄存器
与CPU架构不同的是,GPU的每个SM拥有一个巨大的寄存器文件,它通常包含上千个寄存器,例如在费米架构的设备上,每个SM拥有32KB的寄存器空间,这些寄存器平均分配到每个SP,根据线程的数量,每个线程可以使用几个到几十个寄存器。寄存器的读取速度是最快的,约相当于1个GPU时钟周期。
之所以使用数量巨大的寄存器,其一是因为即将在下一节讨论的延迟隐藏的需求,其二是因为GPU寄存器的特征。GPU中的寄存器与CPU中的寄存器是不同的,在CPU中,指令执行完后写入寄存器中的数据会被自动写入到缓存中去,然后缓存系统会广播更新多处理器架构中其他处理器的缓存,以及将数据写入到主内存。然而GPU并不会这么做,写入到寄存器中的数据会一直停留在该寄存器中,直到有新的数据写入或者当前线程执行完毕自动退出,寄存器数据被重置。这就是称为程序托管的内存模型的原因,程序员指定一个变量的内存类型,即是指定了其数据的存放位置,处理器不会自动变��更这个位置。
这样做的原因是什么呢?由于GPU可能同时处理上千个相同指令的线程,每个线程在执行过程中某些中间计算结果只供自己所在的线程使用,所以它完全没有必要写入到全局内存中去。在一个GPU内核函数中,每个本地变量都会自动存储到寄存器,这些变量不会被自动更新到全局内存,只有当该线程计算结束,或者某些中间过程需要将数据写入到全局的时候,才将寄存器中的数据赋值给全局内存变量,这样将大大节省不必要的数据在内存中的流通,例如在一个OpenGL的着色器程序中,通常只有最后才会将结果写回到全局内存,这些值可能是顶点着色器中执行过变换的坐标值,或者像素着色器中计算出的颜色值。但同时这也需要每个线程拥有大量的寄存器,因为每个本地变量都需要占用一个寄存器。
此外,每个SP线程都拥有自己独立的寄存器还可以避免线程切换时导致的寄存器数据的换进换出。在CPU中,当一个线程处于延迟等待状态时,处理器会切换到其他准备好的线程进行执行以隐藏延迟,GPU同样使用了延迟隐藏技术,如下一节所述,并且它更是将延迟隐藏技术发挥到极致,而大量的寄存器导致GPU线程切换的成本几乎为0。
图形处理器架构
本节我们以Nvidia当前的旗舰消费级开普勒(Kepler,[citea:NVIDIAsNextGenerationCUDATMComputeArchitecture:KeplerTMGK110/210])架构为例讨论图形处理器的架构,如图(4)所示(Nvidia下一代图形处理器架构为Pascal[cite a:PascalArchitectureWhitepaper])。

图(4):Nvidia开普勒架构的GK110/210系列处理器
GPU通常是和CPU组成一个非对等的计算环境,其中CPU充当宿主程序,并负责计算一般的串行程序,而另一些计算密集,具有高度并行性特征的程序则被发送到GPU执行。这些仅在GPU上执行的并行计算程序称为内核函数(kernels),CPU负责在GPU上分配内存,并将内核函数以及相关数据发送到GPU内存,GPU的计算单元从这些内存获取数据并进行大规模的并行计算,最后CPU从GPU内存中取回计算结果。
GPU实际上是一个SM阵列,这就是GPU具有可扩展性的关键因素,如果向设备中增加更多的SM,GPU就可以在同一时刻处理更多的任务,例如使用开普勒架构的GK110/210系列处理器拥有15个SMX(注意,由于开普勒较上一代处理器有很大改进(其中比较重要的调整是将之前费米架构中每个线程每个时钟周期内执行2条指令,改为每个时钟周期执行一条命令。这虽然减少了一半的吞吐量,但是开普勒架构拥有更多的内核,以及减少“时钟频率”带来的能量消耗等问题,开普勒架构较前代仍有大幅性能的提升。),所以Nvidia称其新的流处理器族为SMX而不是SM)。
每个SMX中包含若干个流处理器SP以及其他一些关键部件,如寄存器,共享内存,硬件支持的特别计算单元(Special function units,SPU)等。在每个SMX内执行的是相同的指令,因此它们只需要一次指令获取,然后广播到SMX内的各个SP,所以SMX使用的是SIMD架构模型,但是Nvidia更趋向于称之为SPMD,即单程序多数据(Single Program Multiple Data)。
开普勒架构的GK110/210均提供每个SMX内部192个SP,所有理想情况下每个SP每个时钟周期可以同时执行192个线程,这使得GK110/210均可以提供的每秒浮点数计算次数(Floating Point Operations per Second,Flops或Flop/s)高达1TFlop/s(1T=)。
当然,图形处理器的硬件架构还包括很多知识,然而本书并不是一本描述并行计算的书籍,这里讨论处理器架构的目的是用来帮助我们理解并行程序的执行以及它的一些特性,然而我们并不需要理解它内部到底怎么执行,感兴趣的读者可以阅读[citea:NVIDIAsNextGenerationCUDATMComputeArchitecture:KeplerTMGK110/210,a:PascalArchitectureWhitepaper,a:CUDACPROGRAMMINGGUIDE]等以了解更多关于并行计算的知识。
延迟隐藏
由于处理器时钟频率和主内存读取速度以及带宽的差异,导致数据从主内存传输到处理器计算单元的过程存在很大的延迟,例如全局内存的访问高达个时钟周期。
为了克服这种延迟,一些技术通过一些辅助手段来“隐藏”这种延迟,这种技术称为延迟隐藏(Latency hiding)。在CPU中主要使用缓存来隐藏延迟,缓存系统一次性读取一个缓存行的数据,如果指令之间处理的数据是连续的,那么同一缓存行内的后续的数据的延迟将被隐藏;另一方面,如果数据来自于下一个缓存行,则可以使用预取技术来提前缓存相邻的缓存行来达到延迟隐藏。
然而,这种基于硬件托管的缓存系统并不适于大规模的并行计算,由于硬件托管的缓存系统会自动将所有写入寄存器的值更新到缓存系统以及主内存中,而并行计算线程之间独立性比较高,大部分中间计算结果都不需要写回缓存中去,所以GPU使用的是程序托管的内存模型。并且,GPU中虽然仍然会使用缓存,然而GPU的缓存系统主要面向一些共享数据(部分线程之间或全部线程之间共享),对于大部分独立的线程数据,GPU使用另一种方式来隐藏延迟。
回想前面讲述单个处理器的多线程技术,当一个线程处于延迟状态时,处理器自动切换到其他处于等待执行状态的线程进行执行,这样通过使用多于处理器能够处理个数的线程数目,内存读取的延迟也能够在一定程度上被隐藏。
GPU正是将这种延迟隐藏技术发挥到了极致,要放大这种技术的隐藏作用,有�两个方面可以改进,其一是使用能够容纳更多的等待线程。在GK210/110架构中,虽然每个SMX只有192个SP,但是每个SMX可以分配最多高达2048个线程,即是说当每个时钟周期有192个线程在执行计算的时候,还可以有将近2000个线程正在从内存中获取数据,这样通过大量的线程就使得大部分线程的内存获取的延迟被隐藏了。
CPU多线程技术的另一个瓶颈来源于少量的寄存器,虽然每个时钟周期可以容纳多个线程处于延迟状态,但是由于寄存器数量的不足,这些线程的数据被放入在缓存系统当中,使得每次切换线程时都需要寄存器数据的换进换出,因此执行多线程就需要大量的延迟。GPU同样用到上下文切换的概念,但是它拥有数量众多的寄存器,它致力于为每一个线程都分配真实的寄存器,哪怕是处于等待状态的线程,这正是它隐藏延迟的秘密所在,因此,一次上下文调换只需要重新执行另一个寄存器组。在GK110架构中,每个SMX有65 536个32位的寄存器,GK210更是高达131 072个32位寄存器。使得每个线程可以拥有多达32(65 536/2048)个以上寄存器可用。
此外,利用这种延迟隐藏技术,还可以实现内核的执行与从CPU到GPU内存的传输重叠进行。如图(5)所示,如果内核函数直接从CPU而不是从GPU的全局内存获取数据,就可以不需要等待所有数据都传输至GPU之后再开始执行内核函数的计算。由于并行计算提成涉及大量的数据集,这种重叠技术可以使得GPU的利用率更高(不需要在CPU向GPU传输大量数据集的时候空闲等待)。

图(5):内核执行与内核传输重叠进行
全局��内存访问的合并
并行计算的性能,还可以得益于其程序和数据的一致性,这种一致性越高,能够实现的吞吐率就越高,反之数据的存储越发散,则将导致更低的吞吐率。所以,除了需要管理内核函数变量的内存位置,并行计算的另一个难点还在于程序员需要去精心设计全局内存数据的布局。
GPU使用一种称为内存合并(Memory coalescing)的技术来充分利用并行程序的数据连续性。当连续的线程向全局内存发起数据请求,并且请求的内存块是连续对齐时,这些线程的多个内存请求会被合并成一次请求,然后一次性返回所有数据。一般可以返回整个线程束所需要的数据,如图(6)所示。SMX中的线程每32个会被组成一个线程束(Thread wrap),每个线程束内的线程会被保证并行执行。由于一个存储事务是需要一定开支的,内存合并使得多个线程的内存请求只需要一个存储事务即可解决问题。

图(6):一个线程束内相邻线程对相邻连续对齐的内存的读取将会被合并成一次读取,大大减少存储相关事务的开支
内存会基于线程束的方式进行合并,内存合并事务大小支持32,64以及128字节,分别表示线程束中每个线程以1,2以及4个字节为单位读取数据。全局内存支持单个指令读或写的请求的内存大小为1, 2, 4, 8, 或者 16 字节,要想获得内存合并,每个线程访问的数据必须基于这些基础数据对齐的,否则将不能获得内存合并的好处。所谓对齐(align),即是指每次指令获取的数据所占内存��大小是和内存系统支持的存取单位一致的,例如一个数据所占内存大小为10字节,将导致返回一个16字节的数据,这个数据类型就是没有对齐的。
所有内置类型如char, short, int, long, longlong, float以及双精度的float2 和 float4都是自动对齐的,对于用户自定义的数据类型,其可以使用对齐标识符__align__ 进行强制对齐(但这样将导致一些未定义的数据浪费内存,所以通常我们应该精心设计自定义类型以充分利用内存合并以及内存的占用),如:
struct __align__(8) {
float x;
float y;
};
或者:
struct __align__(16) {
float x;
float y;
float z;
};
分 支
最后我们要讨论的是条件分支指令,传统的CPU的目标是执行串行代码,它们包含了一些特殊硬件,例如分支预测单元,多级缓存等,所有这些都是针对串行代码的执行;但GPU并不是为执行串行代码而设计的,为了高效执行大量的并行计算,GPU并没有像CPU那么复杂的硬件实现的分支预测功能,同前面的变量内存位置分配,数据的连续对齐一样,条件分支同样需要程序员小心地处理。
对于分支指令,GPU在执行完分支结构的一个分支后会接着执行另一个分支,对不满足条件的分支,GPU在执行这段代码的时候会将它们设置成为激活状态,当这块代码执行完毕之后,GPU继续执行另一分支。这种机制是由于每个SMX内的每个线程束每次只获取一条指令,它不能同时获取条件为真和条件为假两条指令。
这样导致的结果就是,当程序中包含分支指令时,如果在一个线程束内的分支分布是不连续的,例如图(7)(b)所示,则将导致在处理分支的时候部分线程处于空闲状态,不能充分利用GPU的计算资源。更糟糕的是,这种由于分支导致的线程并不会导致处理器将计算资源切换到其他线程束执行,即是说,由于分支导致的部分线程的闲置并不能算作线程阻塞,只有内存读取的延迟才能促使线程切换。



图(7):GPU并没有复杂的分支预测单元,这是由于其SIMD架构特性决定的,SIMD在一定的数据内只获取指令一次,所以不连续的分支将导致资源闲置,但是连续的分支分布则可以避免这种闲置
不过在指令的层面,硬件的调度是基于半个线程束,只要我们能够将半个线程束中连续的16个线程束划分到同一分支中,那么硬件就能同时执行分支结构的两个不同条件的分支块。然而这种条件非常苛刻,对于分支指令,最有效的方法是尽量保证分支的连续性,对于所有线程组成的条件数组排序,或者以某种方式的处理,使得分支能够连续排列。例如如果条件是大于某个数,则可以让数组中的元素以分割进行排列,左边的数全部大于,而右边的数全部小于或等于,这将导致分支分布比较连续,仅在分割的位置或者两端可能出现分布不连续。由于一个大型的并行计算常常有上万的线程,因此这种小小的优化也可以带来一定的性能提升,分支分布连续的指令执行如图(7)(c)所示。