2.2 并行计算架构
本节我们讨论CPU并行计算的一些概念,并行计算架构的演变,怎样由单处理器多线程架构,到多处理器架构。通过对这些架构的演变及特点的讨论,我们能够很好地了解并行计算的概念,同时最重要的,现代GPU并行计算架构正是基于这样一些技术发展而来,并且我们能够很清晰地认识到GPU并行计算与CPU并行计算的特征和区别,以使我们更好地学习后面的渲染管线。
指令级并行
一个简单的公式可以用于度量一个单处理器的计算性能:
(式1)
因此,对于一个单处理器,每秒钟可执行的指令数量对处理器性能的影响至关重要,本节要讨论的内容就是指令级的并行计算(instruction-level parallelism,ILP),它是指一个单处理器同时执行多条指令的能力。考虑以下串行程序:
1. e = a + b
2. f = c + d
3. m = e * f
操作3依赖于操作1和2的结果,所以它必须等操作1和2完成之后才能执行。然而操作1和2之间并不存在依赖关系,所以它们可以被同时执行。如果我们假设以上3个操作都可以在一个周期内完成,那么全部完成3个操作的时间为2个周期,则一个周期内的指令并行数ILP值为3/2。
指令级并行技术的目标就是要尽可能地提升ILP值。通常程序员编写的程序都是串行的,其编译的指令按照一定顺序一个接着一个地执行,ILP技术 允许编译器和硬件重叠地执行多个指令,或者甚至按不同的顺序执行指令。ILP对程序员是透明的(然而我们将看到明白指令级并行的一些技术对于编写高性能程序仍有一定的指导作用),这与下一节即将讲述的单处理器多线程技术相反,后者需要程序员显式地区分可以被并行执行的线程。
由ILP的定义可知,对于相同的处理器,其ILP值是随着程序的不同而不同的,因为它跟特定程序的可并行能力有关,指令之间的依赖越少,其可并行能力越强,ILP值越高,反之则越低。硬件对串行程序执行指令级并行处理的技术有很多,本节讨论一些比较流行的ILP技术。
指令管线化
第一种是指令管线化(instruction pipelining),它也是各种ILP技术最重要的基础,它是指将一条指令完整的执行流程分成多个阶段,例如获取指令,解码指令,获取操作码等,每个阶段允许一条单独的指令执行。这样的划分有一些重要的原因,处理器内部针对这些特定的阶段都有专门的计算功能,如果一次只处理一条指令,那么当其中任何一个阶段发生延迟或者缓存失效时,都会导致其他功能处于等待空闲状态,不能充分利用处理器的资源。
根据实现的不同,处理器对指令处理的阶段划分也不相同,有些处理器将指令管线阶段划分为多达20,甚至30多个阶段。我们以最经典的5步划分法1为例,这5个阶段包括:
-
IF: 获取指令(instruction fetch)阶段,处理器从一级指令缓存L1I$获取一个32位(如果是64位机,则指令长度为64位。)的指令,该操作通常具有1个时钟周期的延迟。在这个阶段,一个称作程序计数器(program counter,PC)的寄存器用来保存当前被执行指令在缓存中的地址,它被用于提供给PC预测器(PC predictor),PC预测器用这个地址直接获取指令缓冲区的一个指令,并同时将程序计数器的地址增加4(或者8,因为每条指令的长度为4个字节),以将程序计数器更新到下一个连续程序计数器。这种简单的预测方式通常会在当前指令处发生分支或跳转的时候出现错误,从而导致下一次指令获取出现指令缓存失效,我们上一节讲述的指令预取技术将在这个阶段进行计算。
-
ID/RF: 解码指令以及从寄存器获取操��作数(instruction decode and register fetch)。
-
EX: 执行(execute)。
-
MEM: 读取内存(memory access)。
-
WB: 写回寄存器(register write back)。
由于将指令计算过程管线化,每个管线阶段都允许执行一条指令(每个时钟周期执行该指令的一个阶段),与工厂生产流水线的原理类似,指令管线化通过充分利用各个生产流水线,而不是需要等一个单一产品的一个阶段完成才能开始下一个阶段(导致每次除工作之外的其他流水线空闲),提高了整个管线的吞吐能力。
指令管线化得工作方式如图(1)所示:在第1个时钟周期,处理器读取指令1的指令;在第2个时钟周期,处理器对指令1进行解码并同时获取指令2的指令;在第3个时钟周期,处理器执行指令1,同时解码指令2以及获取指令3;以此类推,理想情况下,从第5个时钟周期开始,处理器每个时钟周期内将能同时处理5条指令。

图(1):指令处理的管线化,通过充分利用处理器的各个功能,管线化能够使处理器同时处理多条指令,提高了处理器的吞吐率(图片来自Cburnett)
然而指令管线化并不能减少延迟,当这些指令对应阶段出现延迟时(例如缓存失效,或者需要等待其他指令完成才能执行),该指令将处于停止等待状态。如果处理器每个时钟周期都能获取新的指令,处理器的利用率就能达到最大,否则这些处于等待状态的指令就会抑制对新指令的读取,降低了吞吐率。
和其他所有ILP技术一样,指令管线化的工作效率取决于应用程序的可并行性。指令管线化假设所有指令都是可以并行执行的,当程序中的指令出现依赖时,称之为一个障碍(hazard)。当然,在一般情况下,程序员不需要理会程序指令级的可并行性,而只管专注于程序逻辑编写串行代码,编译器和硬件会帮助我们对指令进行并行化以减少或避免障碍,但是编写高性能的程序则需要程序员理解这些硬件处理的方式。
通常硬件使用三种主要的方法来处理串行指令的并行障碍:
- 管线气泡(pipeline bubble)
- 操作数前移(pperand forwarding)
- 乱序执行(out-of-order execution)
管线气泡
管线气泡是最简单的一种处理方式,当指令包含有障碍时,其将在解码阶段被识别,同时处理器会创建一个气泡占据该指令的解码阶段,使当前管线的解码阶段处于空闲等待状态,管线气泡将导致后续一个或多个指令被延迟。
如图(2)所示,在第3个时钟周期时,紫色指令在解码阶段发现障碍同时创建气泡暂停该阶段,这里紫色指令可能需要依赖于绿色指令的输出值,气泡的出现导致后续的蓝色和红色指令被延迟一个时钟周期;在第4个时钟周期,绿色的指令可以继续前进,并产生输出值,使得紫色指令可以解码继续前进,然而此时指令管线中并没有指令进入执行阶段,以此类推,使得气泡沿管线指令方向前进,直至被挤出指令管线。在这种解决方案中,每个气泡表示该时钟周期有一个阶段处理空闲状态。

图(2):管线气泡法在指令遇到障碍时创建一个气泡使阶段处于等待状态,直到其相应条件满足指令才继续前进,由于气泡导致下一个时钟周期的下一个阶段没有指令可执行,因此气泡必须沿着指令管线方向前进直至被挤出指令管线(图片来自Cburnett)
操作数前移
当出现指令间的依赖关系时,后面的指令必须等待前面的指令执行完毕并将数据输出寄存器,后面的指令才能继续往下执行,数据写入以及从寄存器读取的过程可能占据几个时钟周期,所以上述的气泡在指令管线中停留的时间可能大于3个时钟周期以上。考虑如下两条指令:
1. ADD A B C #A=B+C
2. SUB D C A #D=C-A
由于指令2中操作数A的值依赖于指令1的输出,如果指令管线每个阶段只占据1个时钟周期,则这两条指令的执行将导致指令2被延迟3个周期,如表(1)所示(也可以从图(2)看出这种关系):
| 指令 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | IF | ID | EX | MEM | WB | ||||
| 2 | IF | stall | stall | stall | ID | EX | MEM | WB |
表(1): 在经典的5步指令管线划分法中,前后相邻且在每个阶段占据1个时钟周期的假设下,指令2将被延迟3个时钟周期
观察表(1),指令2的ID阶段和指令1的EX阶段处于同一个时钟周期,如果能够在芯片集成电路内部直接将指令1的值传递给指令2,而直接绕开寄存器,那么其将能够直接避免掉这种前后依赖关系导致的障碍。操作数前移正是基于此原理用来克服指令障碍的方法,在操作数前移方法中,处理器需要对指令探测这种依赖性的存在,然后根据探测结果判断是需要从寄存器中获取操作数,还是直接通过相关的电路直接获取前一指令的值。操作数前移的操作如表(2)所示。由于程序中通常存在大量这种前后依赖关系,操作数前移技术不仅能够有效避免这种障碍,而且大大节省了数据在寄存器之间存储和读取导致的时间延迟。
| 指令 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | IF | ID | EX | MEM | W | ||||
| 2 | IF | ID | EX | MEM | WB |
表(2): 在操作数前移技术中,如果处理器探测到依赖性的存在,则直接将前一指令计算的结果传递给后面的指令,避免了气泡导致的延迟
乱序执行
乱序执行(out-of-order execution,OoOE)技术基于这样一个事实,即如果后面的指令不依赖于前面的指令,或者说它此时具备执行指令需要的操作数数据,则它可以先于前面的指令被执行。这种顺序的调整导致其程序指令被执行的顺序(称为数据顺序,data order)跟程序本身被编写的串行顺序(称为程序顺序,program order)可能不一样。
尽管指令被执行的顺序发生了改变,然而乱序执行必须保证指令执行结果输出的顺序与程序顺序保持一致,以保证最终程序运行的正确性。乱序执行的指令执行步骤如下:
- 获取指令。
- 将指令分配到一个指令队列。
- 指令在指令队列等待,直到其输入操作数可用,此时它可以早于自己前面的指令被执行。
- 执行指令。
- 将指令输出结果保存在一个队列中。
- 只有当一个指令的之前所有指令被执行完毕,并且其结果被写入到寄存器之后,才将该指令的结果输出到寄存器,以保证执行结果的顺序一致。
分支预测对指令管线的影响
除了指令间的依赖关系,前面讲述的分支预测也可能会对指令管线的性能有比较大的影响,考虑如图(3)所�示的分支语句,程序执行时正确的分支流向为AEFG,我们来分析如果分支预测器预测的结果为ABCD会发生什么情况。
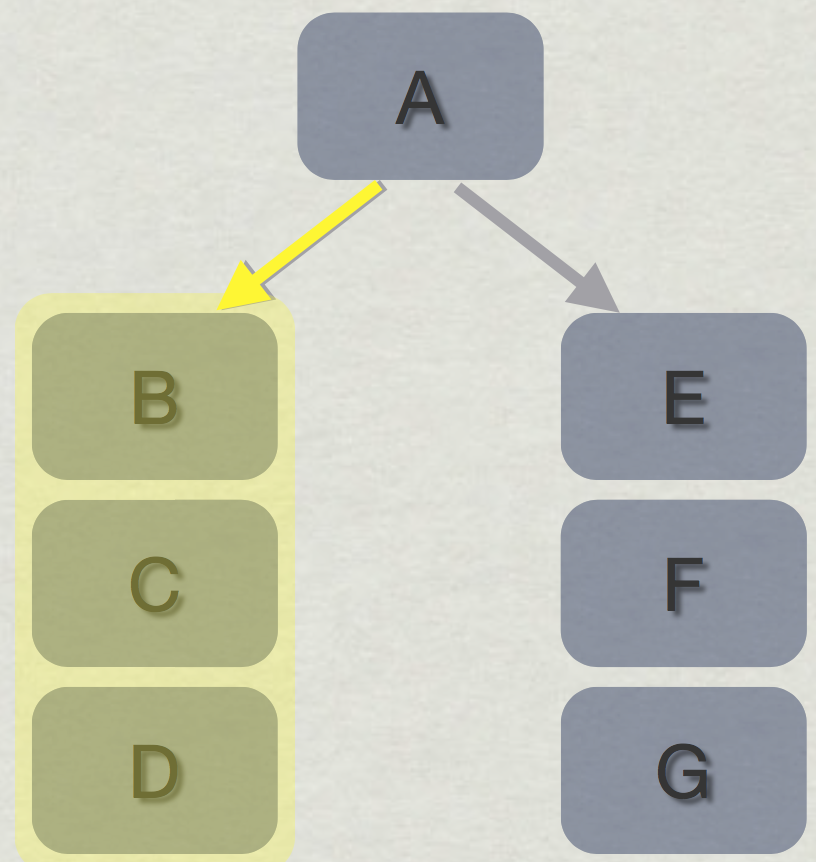

图(3):分支预测失败会导致处理器放弃并销毁之前所有未执行完且判断错误的分支指令(图片来自\cite{a:DoggedDetermination:TechnologyandProcessatNaughtyDogInc.})
由于分支的真实走向必须等到if比较指令执行完毕,并且将结果写入到寄存器之后,处理器才会知道真正的分支走向。在这个例子中,即是必须等到A指令执行完毕,在A指令的第4个时钟周期之前,B,C及D指令会依次被执行,等到第4个时钟周期A指令计算完毕之后,在第5个时钟周期开始,处理器将重新将正确的EFG指令载入执行单元执行指令计算,同时销毁之前所有关于BCD在寄存器中的数据及其他相关状态。这种代价在指令管线的阶段划分越多时越严重,因为有更多不应该被执行的指令被执行了一部分,之后整个状态还需要被重置。
此外,如果if比较函数是对两个浮点数进行比较,则代价更高。浮点数比整数的比较要花费更多的时钟周期,这会导致那些被错误执行的指令被执行更多的指令阶段,从而造成处理器资源的更大浪费。
由于条件分支导致处理器资源浪费,现代处理器大都采用一种方法来避免比较和跳转操作,从而能够减轻分支带来的性能开支。这种方法基于一个第三个参数,来在两个操作数之间进行选择,而不需要执行比较和跳转指令,这种方法称为条件转移(conditional move)。
条件转移类似于C++中的三元操作符,在处理器中,一个浮点数条件转移操作符称作fsel,它是浮点数选�择(floating-point selection)的简称,它具有如下的指令形式:
fsel f0, f1, f2, f3 // f0 = ( f1 >= 0 ? f2 : f3 )
该指令直接将f1与0.0进行比较,然后直接选择f2或者f3,这是一个单条指令,不包含分支或者跳转。编译器往往能够将三元操作符直接转换为fsel操作符:
return a >= 0 ? b : c; --> fsel fr0,fr1,fr2,fr3
甚至如:
// float a, b, c, d, e, f;
return ( a >= 0 ? b + 1 : c + 2 ) + ( d >= 0 ? e + 1 : f + 2 ) ;
也可以转换为:
fr1 = a, fr2 = b, fr3 = c,
fr4 = d, fr5 = e, fr6 = f
fr0 = 1.0f, fr13 = 2.0f
fadds fr12,fr2,fr0 ; fr12 = b + 1
fadds fr11,fr3,fr13 ; fr11 = c + 2
fadds fr10,fr5,fr0 ; fr10 = e + 1
fadds fr9,fr6,fr13 ; fr9 = f + 2
fsel fr8,fr1,fr12,fr11 ; fr8 = a >= 0 ? fr12 : fr11
fsel fr7,fr4,fr10,fr9 ; fr7 = d >= 0 ? fr10 : fr9
fadds fr1,fr8,fr7 ; return = fr8 + fr7
通过上面的示例可以看出,fsel对两个输入值都需要进行计算,即相当于计算了原来if条件语句的两个分支语句。然而即便如此,fsel带来的性能提升仍然十分明显,这得益于它直接省略掉了分支选择,尤其是当程序中有大量if条件语句并列,或者在一个循环语句中穿插if条件语句等情形,这些带来的处理器资源浪费极大。当然fsel只处理浮点数的比较,读者可以从[citea:ThePowerPCCompilerWritersGuide]了解更多信息。在[citea:DoggedDetermination:TechnologyandProcessatNaughtyDogInc.]中,Jason Gregory建议对于高性能部分,尽量使用fsel指令,并且拆分循环内的条件语句,尽可能地使用简单的,少分支的算法。
线程级并行
上一节我们介绍了指令级的并行技术,这些技术大都通过硬件来实现,其中编译器能够针对这些硬件实现进行一定的优化,但是它们对于程序员而言一般是透明的。此外,指令级的并行技术还包括其他很多比较流行的技术实现,我们所讨论的几乎都是能够对编写代码具有一定指导意义的技术,这能够帮助我们编写更高性能的代码,毕竟实时的游戏程序对性能有着贪婪的要求。
在计算机科学中,一个最小单元的,可以独立被处理器调用的指令的集合称为一个线程(thread),在前面讨论的指令级并行技术中,在处理器中执行的一个单独的程序即可以称为一个单线程。在单个处理器内部,即使使用前面讲述的指令并行技术,只同时执行单个线程的处理器的利用率通常仍然很低,其原因是某些操作需要很长时间的延迟,例如数据密集型的程序需要加载大量的数据,或者线程需要等待外部的输入事件或者其他系统事件。为了进一步提高单个处理器的计算性能,多线程技术应运而生。
多线程(multithreading)技术是指在单个�处理器或者一个多核处理器的其中一个核内部,拥有同时执行多个线程的能力,它区别于后面即将讲述的多处理器架构,这些线程在内部共享该处理器的各种资源,包括计算单元,寄存器,缓存等。
在现代操作系统中,多线程技术是直接被操作系统支持的。不同于指令级并行是对用户透明的,为了充分利用多线程技术,程序员需要将一个程序中可以独立并行执行的部分拆分成单独的线程,然后操作系统根据一定的规则控制和调度处理器执行这些线程。如图(4)所示,每个应用程序可以拥有一个或多个线程,其中至少一个主线程(primary thread),以及零个或多个次级线程(secondary thread),每个线程被赋予一定的优先级,这些线程被放入到一个线程池,操作系统以线程为单位将这些程序指令发送到处理器进行执行,其调度的方式通常是基于时间片。
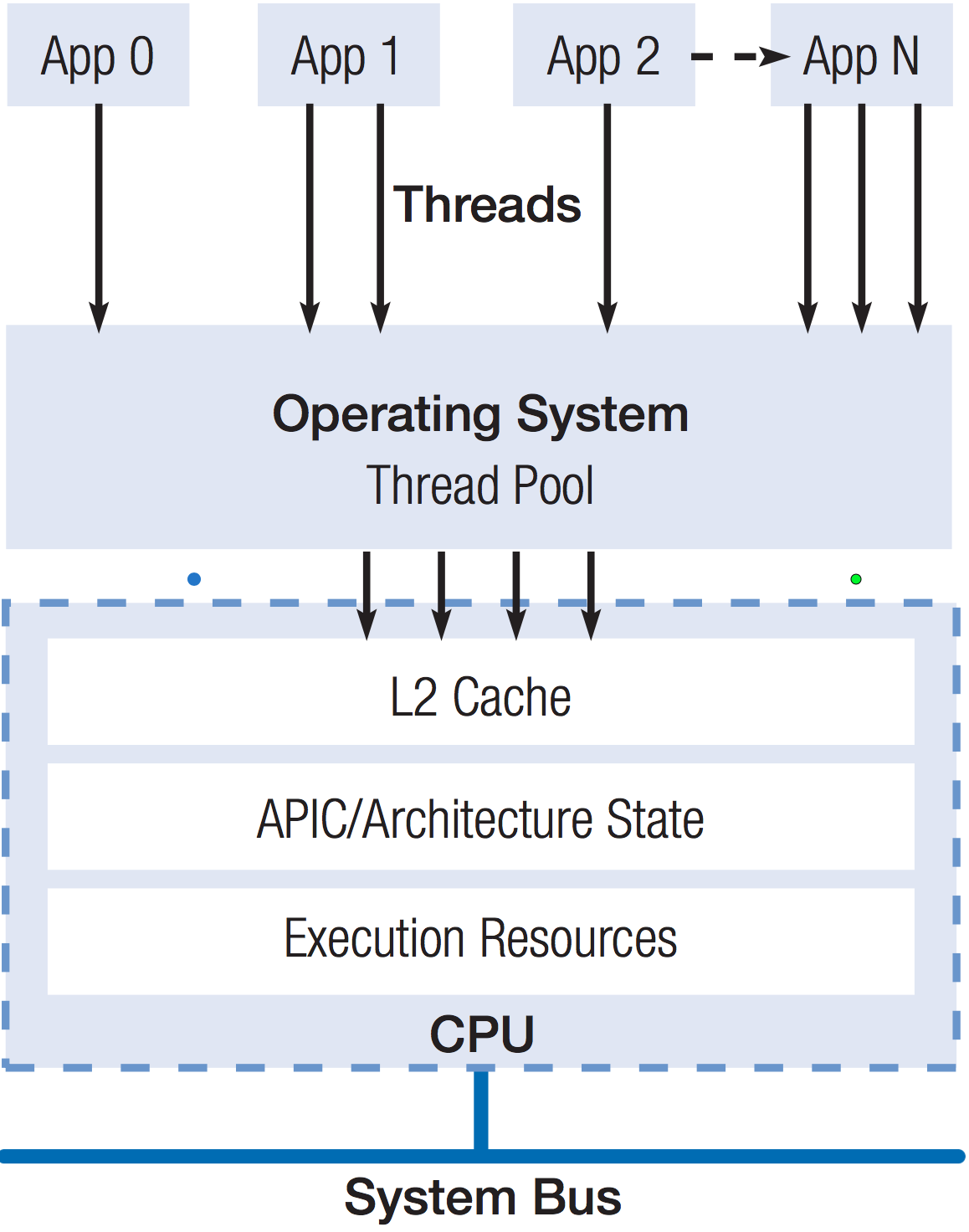
图(4):多个线程可以在一个单独的处理器上执行,每个应用程序可以创建一个或多个线,这些线程并被操作系统按照一定的优先级调用处理器进行处理
如图(4)所示,多线程处理器内部可以支持多个线程并行执行,但是这些线程不是真正地同时执行,而是通过处理器的控制交叉地执行。当当前正在执行的线程遇到缓存失效或者其他事件(例如一个线程需要等待另一个线程的输出结果)时,处理器即自动切换到其他处于等待执行状态(ready to run)的线程(即数据已经加载到缓存)执行指令,通过这样保持处理器的繁忙,避免处理器等待数据从主存读取的延迟,来充分提高单个处理器的计算性能。
使用硬件对多线程技术的支持的一个目标是,允��许在等待延迟的线程和已经准备好被执行的线程之间保持快速切换,为了达到这个目标,每个线程都需要拥有自己的指令和数据寄存器集合,还包括用于存储指令管线调度相关的一些处理单元和调度信息,当发生线程切换时,直接在高速的寄存器之间执行赋值和读取即可,而不需要重新从缓存读取数据。现代处理器的线程切换通常可以在一个时钟周期内完成。
单处理器多线程技术的这些核心思路后来被用于GPU架构中,主要包括始终切换到处于‘准备好’的状态的线程,以及使用更多专有的寄存器来实现线程之间的快速切换。当然GPU会有一些自己独特的“思维”,但是其核心架构都是随着CPU并行计算的发展而演变出来的,再结合下一节的多处理器技术,我们就可以推导出一个可以具有无限扩展,并且能够高效利用每个GPU处理器计算单元的并行计算模型。
同时多线程技术
多线程技术有多种实现方案,最简单的是块多线程(block multithreading),这种方案会一直执行一个线程,直至线程遇到很大的延迟(例如缓存失效,这种延迟可能需要上百个时钟周期)时切换到另一个处于“可执行状态”的线程。
另一种比较聪明的方案称为交叉多线程(interleaved multithreading),这种技术在每个时钟周期都使用一个不同于上一个时钟周期的线程。由前面的内容可知,当处理器在执行一个线程时,指令级并行会使得该线程内多条指令可以被同时执行,这主要通过指令管线来实现,然而指令之间常常有数据依赖关系,而使得后面的指令在管线中使用气泡填充,虽��然有一些指令级的技术用于减少气泡的占用时间,交叉多线程则试图通过线程级的技术来解决这个问题。因为线程之间是相对独立的,所以交叉多线程每次从不同的线程中取出一条指令加入到指令管线中,这样理想的情况下指令管线中每个阶段执行的是不同线程中的指令(这里可能比较费解,回想前面讲述的指令管线知识,虽然每个时钟周期内每个管线阶段执行的是不同的指令,但是每个时钟周期处理器只加入一条指令,所以如果每个时钟周期取来不同线程的指令,那么管线各个阶段执行的将是来自不同线程的指令。),从而几乎不会有数据依赖关系。然而交叉多线程的不足是每个指令阶段都需要额外的计算和存储成本用来追踪这些线程的ID。
上述两种方案都可以称为时分多线程(temporal multithreading,TMT)技术,在TMT中,对于给定的任何时间,指令管线的每个阶段只有一个线程的指令在执行,如图(5)左边的架构。本节主要要讲述的,也是现代处理器比较高级的多线程技术方案是同时多线程技术(simultaneous multithreading,SMT),与TMT相对应,在一个给定时间内及指令阶段,SMT处理器可以同时有来自多个线程的指令在执行,如图(5)右边的架构。SMT并不需要对普通的TMT架构做太大改变,它只需要增加在一个时钟周期内从多个线程获取指令的能力,以及更大的寄存器文件用于存储多个线程指令的相关数据。SMT并发线程的数量由芯片设计者决定,通常的设计为每个处理器2个并发线程,但是一些处理器支持8个并发线程。
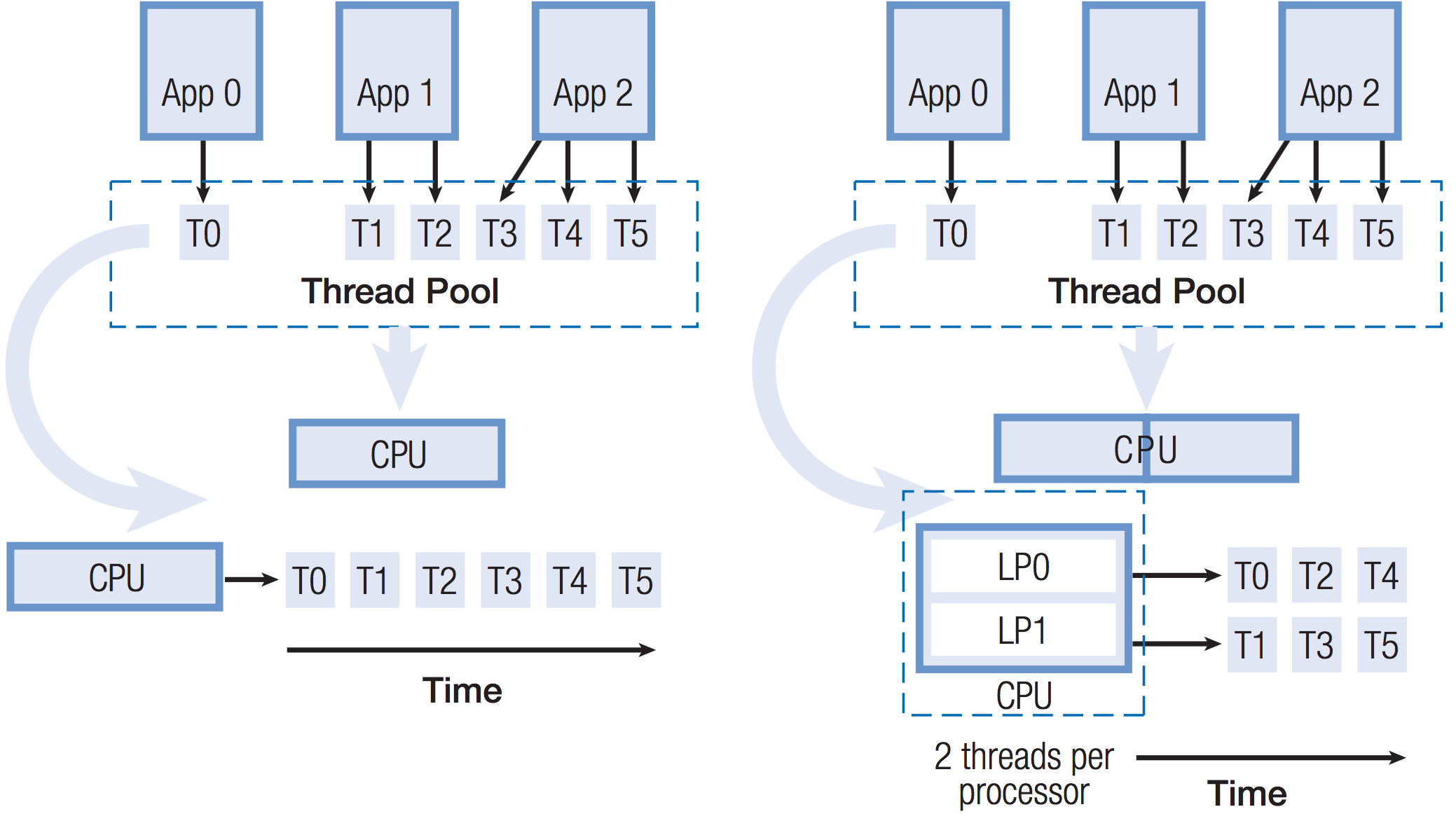
图(5):两种经典的多线程架构,左边为TMT,右边为SMT,SMT在每个时钟周期的每个阶段内,可以同时执行来�自多个线程的指令。从图中可以看出,理论上SMT执行相同数量的指令只需要花费TMT一半的时钟周期
SMT与诸如英特尔的双核处理器是不同的,虽然它们最终都是集成在一个芯片上,但是双核处理器拥有独立的执行单元,指令调度,寄存器,L1缓存等,它们只是共享L2及以上的缓存,我们可以称之为缓存级别的共享;而SMT则是共享指令级的一些资源,接下来将讲述这些共享的资源,通过共享这些指令级的资源,我们看到SMT可以大大提升单个处理器的执行效率。
我们将以英特尔的超线程技术来分析同时多线程技术,英特尔的超线程技术(Hyper-Threading Technology)是一种SMT架构,在结构上,一个超线程架构的处理器由两个逻辑处理器(logical processor)组成,每个逻辑处理器拥有自己的(如架构状态等)一些资源,但是两个逻辑处理器共享处理器的一些执行资源(Processor Execution Resources),如图(6)所示。
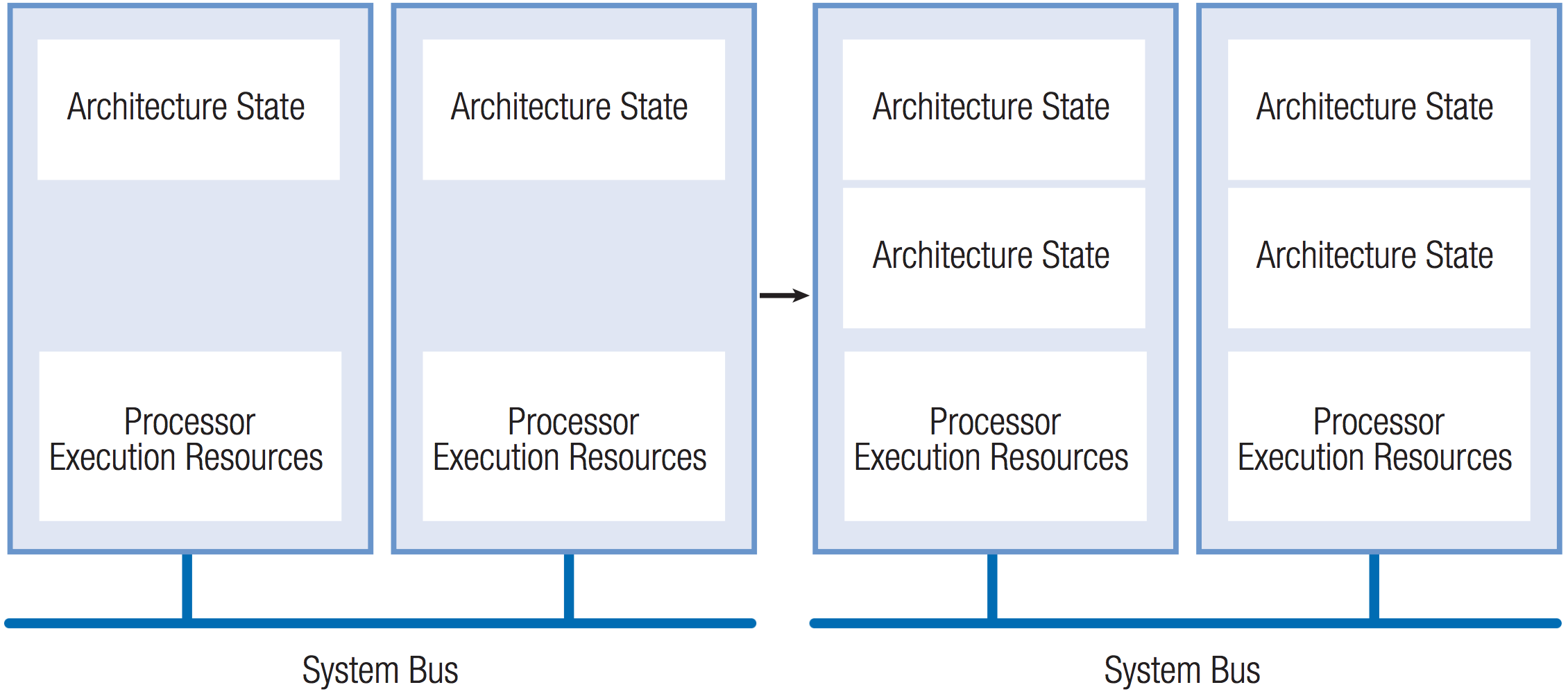
图(6):在英特尔的超线程技术架构中,每个物理处理器包含两个逻辑处理器,每个逻辑处理器包含独立的处理器架构状态,两个逻辑处理器共享除架构状态之外的所有处理器资源。注意图中的计算机是包含两个物理处理器的,或者为后面讲述的双核处理器
每个逻辑处理器拥有的资源包括:
- 拥有独立的架构状态(Architectural State)。
- 并发地执行自己的指令。
- 正在执行的指令可以被独立地打断和停止。
两个逻辑处理器共享:
- 处理器执行引擎(Execution engine)以及L1缓存。
- 共享系统数据总线(system bus interface)。
处理器架构状态包括数��据集,控制,调试等相关的寄存器以及一些状态机相关的寄存器,此外每个逻辑处理器还有独立的高级可编程打断控制器(advanced programmable interrupt controller,APIC)用来控制指令的停止等操作。从一个软件的视角来看,一旦每个逻辑处理器拥有自己的处理器架构状态,它在功能上就相当于两个独立的处理器。相对于整个处理器来说,用于存储处理器架构状态的晶体管只需要很小的面积,它相对于双核处理器大大节省了芯片面积。
超线程技术复制的处理器架构状态用来跟踪程序或线程执行流相关的信息,而其共享的执行资源则包含怎样控制这些执行流的工作展开。所有逻辑处理器共享一个物理处理器除架构状态之外的所有资源,包括执行单元,分支预测,控制逻辑及系统总线等。
[cite a:IntelHyper-ThreadingTechnology]指出,通常应用程序只利用了单个处理器35%的执行资源,而超线程技术可以提高处理器的利用率以达到50%的利用率。
处理器级并行
前面讲述的指令级并行及线程级并行都旨在提高单个物理处理器的执行效率,然而单个物理处理器的计算能力总是有限的,只有进化到处理器级的并行,即拥有能够扩展物理处理器的能力,大规模,可扩展的并行计算才有可能形成。
多处理器架构(multiprocessing architecture)是指一个计算机系统拥有多个物理的处理器,或者拥有多个核(core),两者的主要区别为多核处理器每个核仅拥有L1缓存及寄存器,同一芯片内的核共享L2及主内存,而多个单独的物理处理器往往仅共享主存并拥有自己的缓存系统。
关于多处理器架构,我们可以从两个角度来了解其特点,其一是所有处理器之间的对称性,其二是处理器之间的通信机制。
多处理器架构的对等性
对称性是指所有处理器的地位和功能是否对等,非对等多处理器架构(Asymmetric multiprocessing,ASMP)比较典型的例子是Cell处理器架构,它的思想是用一个常规处理器作为监管处理器,该处理器与大量的高速协作处理器相连。在Cell处理器中,常规的PowerPC处理器担任与流处理器和外部世界的接口,称为PPE(Power Processor Element),而协作处理器SPE(Synergistic Processing Element),则在PPE的管理下处理数据集,如图(7)所示。
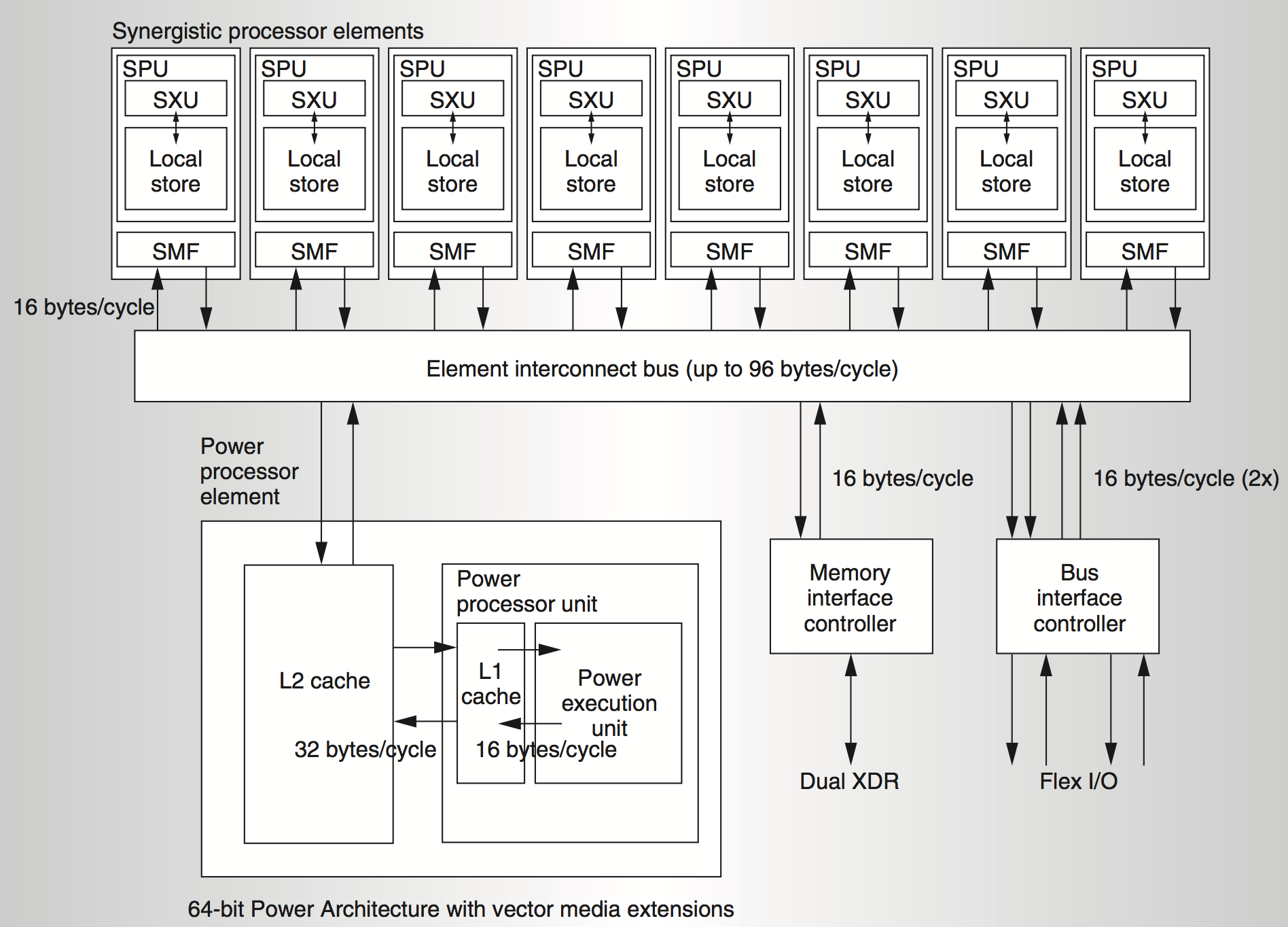
图(7):Cell系统架构,它集成一个PPE处理器和8个SPE处理单元在一个统一的系统架构中,其中PPE是一个普通的64位的Power架构的处理器用于处理一般并行任务,而SPE主要负责数据密集型的计算,所有处理器之间通过EIB相连进行高性能的数据通信,关于更多有关Cell处理器的信息,参见\cite{a:SynergisticProcessinginCellsMulticoreArchitecture}
要想为Cell处理器编程,我们需要写一个在PowerPC核心处理器上运行的程序,该程序会用一个互不相同的二进制码,在每个流处理器单元SPE上,调用执行一个程序。实际上每个SPE本身是一个核,它可以从自己的本地取出一个独立的程序来执行,这个程序与旁边的SPE执行的程序是不同的。另外,通过一个共享的互联网络EIB(Element interconnect bus),SPE之间,以及SPE与PowerPC核之间可以相互通信。
Cell处理器的设计目标之一是克服由于内存访问的延迟对处理器性能的制约,在那个时代的分析显示,即使高速的处理器也浪费约80%的时间用于等待数据从内存读取。因此,即使处理器的计算速度再快,内存访问仍然是一个重要的制约因素。所以,Cell处理器的独特之处在于它摒弃了传统的内存缓存结构,而是直接将数据和指令直接发送到每个SPE处理器的一个本地私有内存空间LS(Local store),SPE直接从LS存取数据,每个SPE拥有一个直接内存存取(Direct memory access,DMA)引擎,用于将LS的数据高速同步到其他SPE或者PPE的内存。
我们对Cell架构感兴趣是因为它很像现代图形处理器的架构,这有助于我们对比和理解下一节的图形处理器。首先SPE主要聚焦于数据密集型计算,例如图像处理以及很多数学物理方面的计算(例如傅里叶变换),这些计算的并行性特征很强,所以每个SPE是完全基于SIMD的数据结构,它简化了寄存器设计,没有像常规处理器一样用于如整数,浮点数指令的各种寄存器类型(整型,单/双精度浮点型,布尔类型,以及地址),它只有一个128位的SIMD寄存器,并用来存储各种数据类型,这些数据类型完全没有针对硬件的特征(例如数据类型在不同处理器上的长度不一致将导致处理器的指令解码等操作需要做一些额外的工作。),这和现代GPU的设计是一致的。这简化了处理器的设计,使得编译器对寄存器的分配也简化了很多,同时大大节省了芯片面积,使同样的芯片面积可以扩展更多的SPE处理器。
另一个和GPU很像的特征是,它摒弃了常规处理器的多级缓存系统,而是直接将数据从主存通过DMA高速读取到LS,为了更有效的工作,我们需要将一个计��算的大量数据提前搬到SPE,让它一次性尽可能做更多的计算,而不是像缓存系统那样每次从缓存系统读取少量的数据。在处理器中,缓存系统占据了很多的芯片面积,并且导致能耗的增加。这种设计架构也能大大减少芯片面积及能耗。
Cell处理器最早被用在PS3中[cite a:PlayStation3SystemArchitecture],然而由于它相对于传统串行编程具有一定的开发成本,并且它不支持乱序执行等特征,以及价格相对比较昂贵,PS4重新又回到了传统的x86架构。然而Cell处理器仍被用于高性能计算,以及其他数学,物理,医学等科学计算中。
对于对等多处理器(Symmetric multiprocessor,SMP)架构则比较简单,更多的处理器主要是增加了并行的能力,应用程序的线程还是通过操作系统来分配,对开发者来讲,我们仅仅需要掌握针对多线程编程的知识即可。
多处理架构的通信方式
由于处理器的计算是以线程为单位的,而线程之间是会共享数据的,因此每个处理器之间需要进行通信,根据这种通信机制的不同,多处理器架构可以分为共享内存以及基于网络的消息传递方式。
在内存共享方式中,每个处理器拥有自己的缓存系统,但是它们共享整个计算系统的主内存,如图(8)所示。基于内存共享的架构方式实现起来比较简单,然而由于缓存是主内存内部分数据的复制,如果同一应用程序的多个线程分布在多个缓存系统内,则需要通过某种同步机制保证各个处理器内的缓存一致性(cache coherence),即一个内存的写操作需要通知所有核的各个级别的缓存,因此,无论何时,所有处理器核看到的内存视图是完全一样的。随着处理器中核数量的增多,这个通知的开销迅速增大,使得缓存一致性成为限制一个处理器中核数不能太多的一个重要因素。缓存一致系统中最坏的情况是,一个写内存操作会迫使每个核的缓存都进行更新,进而每个核都要对相邻的内存单元进行写操作(回想缓存中的数据更新是以缓存行为单位的。)。

图(8):一个共享内存的多处理器架构,每个处理器拥有独立的缓存系统,并通过系统总线共享主内存(图片来自Ferry Milan)
另一种多处理器的架构称为集群,即通过将一些独立的通常是廉价的计算机系统,通过网络等方式联通起来,组成一个多处理器系统。集群的架构具备很高的扩展性,然而由于网络传输的速度很慢,所以处理器之间的通讯具有很大的延迟,它更适合于线程之间的耦合相对比较弱的计算,例如对一张图片的处理,可以把它分成多个部分,如果每个部分的处理是相对独立的,则可以把不同部分发送到不同的计算机上进行计算。
由于缓存一致的的代价,使得共享内存的架构并不太适合高性能的并行计算,所以我们将会看到后面的GPU架构以及前面的Cell处理器架构都是在试图避免使用缓存,来避免缓存一致性的需求。对于那些数据密集型以及高度并发性的程序,将大量数据直接发送到处理器附近的内存,以及使用大容量寄存器来达到高速存储,并且仅对本地数据进行读写操作以减少数据同步的问题,这种简化的架构使得并行计算的性能更高。
弗林分类法
在此之前的所有对处理器架构知识的描述中,我们主要聚焦于处理器的物理结构,对于程序或者编程人员而言,我们提出使用另一种方式来描述处理器架构,即弗林分类法(Flynn's taxonomy),它根据指令流数目和数据流数目对所有的计算机进行分类。其中,流是计算机操作的指令序列和数据序列。利用弗林分类法有4种类型:SISD, SIMD, MISD以及MIMD,如图(9)所示。




图(9):弗林分类法的四种处理器,弗林分类法用来描述处理器架构中数据流和指令流之间的关系,架构类型图片来自Cburnett)
绝大多数标准串行程序设计遵循的都是单指令单数据(Single instruction stream, single data stream,SISD)模型,即在任何时间点上只有一个指令流在处理一个数据项,这相当于一个单核处理器在一个时刻只能执行一个任务。当然,它可以使用所谓的分时机制,即在多个任务间迅速切换,达到“同时”执行多个任务的效果。
在单指令多数据(Single instruction stream, multiple data streams,SIMD)模型中,一个指令流被并发地广播到多个处理器上,每个处理器拥有各自的数据流,如图(9)(b)所示。这样,在处理器内部就只需要一套逻辑来对这个指令流进行解码和执行,而无需多个指令解码通道。由于从芯片内部移除了部分硅实体,因此SIMD相对于其他系统可以做得更小,更便宜,能耗更低,并能��够在更高的时钟频率下工作。
使用SIMD,实际上就是从“对一个数据点执行一个操作”变为“对一组数据执行一个操作”,由于这组数据中的每一个元素的操作是不变的,所以指令读取和解码只需要进行一次。此外,由于数据区间是有界且连续的,所以数据可以全部从内存中一次性取出,而不是一次只取一个数据项(对连续数据进行一次性读取也是图形处理器的重要特征,我们即将看到在GPU中对一个块的数据进行一次性读取,并结合使用大量的线程块来隐藏处于读取状态的线程块。)。
注意此处的SIMD架构和SIMD指令并不是一个概念,虽然它们在意义上是类似的。SIMD指令是指在传统的处理器中,其不仅支持整型,浮点型等常见数据类型进行计算,一般现代CPU还拥有另外的SIMD寄存器来支持向量操作,例如在C++中的向量操作,编译器会转化为SIMD指令,并将一个向量内的4个数据一次性读取到寄存器中,而不是每次只读取一个。
并没有比较知名的系统属于多指令单数据(Multiple instruction streams, single data stream,MISD)模型,提出它仅属于完整性的缘故。
在多指令多数据(Multiple instruction streams, multiple data streams,MIMD)模型中,每个处理单元拥有自己的指令流,并且这些指令流操作自己的数据流,如图(9)(d)所示,绝大多数现代并行系统都属于此类型。