4.3 对分布进行采样
由上节的内容可知,蒙特卡洛方法涉及两个基本的步骤:采样和求平均值,本节就讨论几种不同采样方法。
首先我们定义什么是采样,考虑一个定义域空间以及一个概率密度函数,其中,满足:
(式1)
采样的过程是这样一个算法,它能够从对应的随机变量中产生一系列随机数,使对于任意满足:
(式2)
实际上我们不能直接从产生随机数,在计算机程序中这个过程必须要求首先具有某些基础随机数的一个序列。我们可以借助计算机操作系统提供的函数来产生一个均匀分布的随机数,又称为伪随机数(pseudorandom numbers), 定义这些随机数的值为,它们可以用来作为采样所需的基础随机数。
逆变换算法
逆变换算法是1947年由乌拉姆提出的,它的定义如下:设是连续随机变量,其累计分布函数为,如果随机变量是一个上的均匀分布,则随机变量具有和一样的概率分布。
逆变换算法的直观解释可以由图(1)得出,图中表示的随机变量是[0,1]上的均匀分布,由式[ref eq:mc-continuous-pdf]可知,随机变量中的值落于区间的概率,所以上的均匀分布被映射到满足的随机变量上。

图(1):逆变换算法将一个满足[0,1]上的均匀分布的随机变量,通过映射到满足概率分布的随机变量上
以下我们以一个离散分布的例子来进一步解释逆向变换算法的过程,设一个离散随机变量具有4个可能的值,其对应的概率分别为:和 ,这些概率满足:, 该随机变量对应的概率密度函数如图(2)所示。
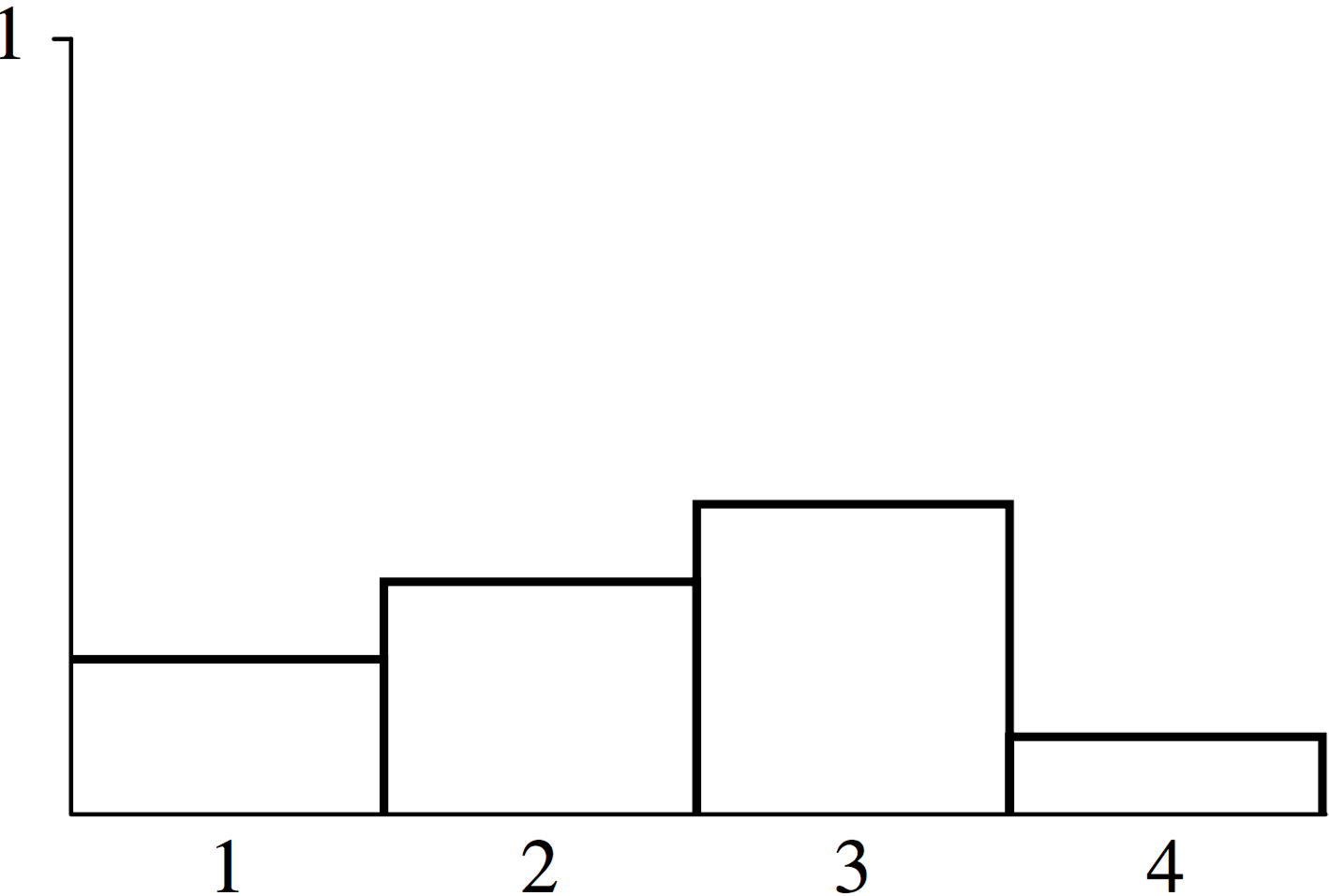
图(2):一个具有4个输入事件的离散随机变量的概率密度分布,每个随机数的概率为
为了使用逆变换算法从一个任意分布中进行采样,首先需要求出其对应的累积分布函数 ,对于连续随机变量,是在全定义域上的积分,对于离散随机变量,可以使用前个的值的和作为的值,如图(3)所示。注意,为了满足所有随机事件的概率之和为1,最右边的条的高度应该为1。
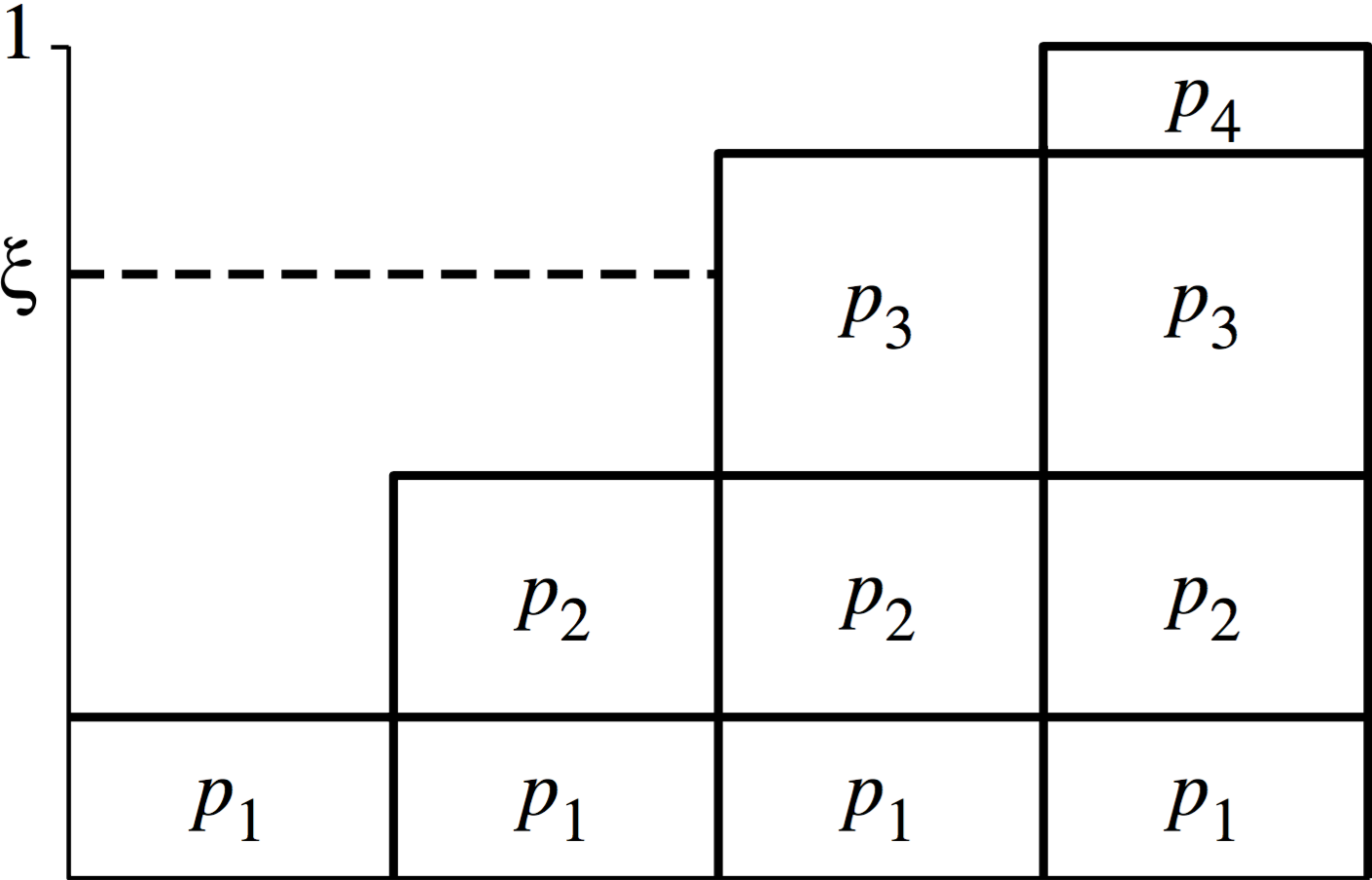
图(3):从离散随机变量的概率密度函数构建概率分布函数的过程,上均匀分布的随机数被按照概率分布映射到离散随机变量上
在图(3)中,一个标准的上的均匀分布的随机变量分布在纵坐标上,通过在水平方向上延伸可以和具有概率的第个输入事件相交,因为是服从均匀分布的,所以具有更大概率的比拥有更多的机会被选择,所以通过这样的方式,上的均匀分布被完全变换为服从概率密度函数的离散随机变量。
通过上述的示例,我们可以推导出使用逆变换算法从一个概率密度函数产生随机数的步骤:
- 首先计算的累计分布函数:。
- 其次计算累计分布函数的反函数:。
- 然后从一个上的均匀分布产生一个随机数。
- 最后将随机数代入的反函数求出满足分布的随机数:。
取舍算法
在许多情况下,逆变换算法无法被使用:首先是某些累积分布函数无显式解析表达式,因此写不出反函数,例如某些概率密度函数没有边界,不能归一化;其次是反函数无显式表达式,因此解不出反函数;再次是在整个求累积分布函数和反函数的过程中,这里面可能涉及大量初等函数的计算,因此采样成本很高。
为了在计算机中对任意分布函数进行采样,冯·诺伊曼于1947年提出了取舍算法(acceptance-rejection method),这种方法不需要对概率分布函数执行归一化,并且它通常只需要直接使用计算机系统提供的均匀分布的随机数即可。
取舍算法的思路很简单,它和本章开头讲述的蒲丰投针(如图[ref f:mc-pi]所示)实验的原理类似,考虑一个任意函数(注意,这里的实际上是一个分布函数,然后在取舍算法中它通常并��不是归一化的,因此我们偏向于称其为更具广泛意义的函数而不是归一化的。)被限定在区间,在此区间外的所有值均为0,如图(4)所示。

图(4):取舍算法在一个能够完全包围住的空间上均匀采样,然后选择(接受)处于函数范围内的采样值用来作为采样值,其他值则被抛弃(拒绝)
在这种情况下产生一个随机变量的过程非常直观,它可以被描述为以下接受-拒绝的过程:
- 产生一个上均匀分布的随机数:。
- 产生一个上独立于的均匀分布的随机数:(是函数的最大值)。
- 如果,则接受,接受的随机数为,否则被拒绝,算法返回到第一步重新产生新的随机数。
需要注意的是,每次采样产生的随机数矢量实际上是均匀地分布于一个矩形区域,因此被接受的随机数矢量则会均匀分布于函数以下的区域,这意味着被接受的随机数服从概率分布。
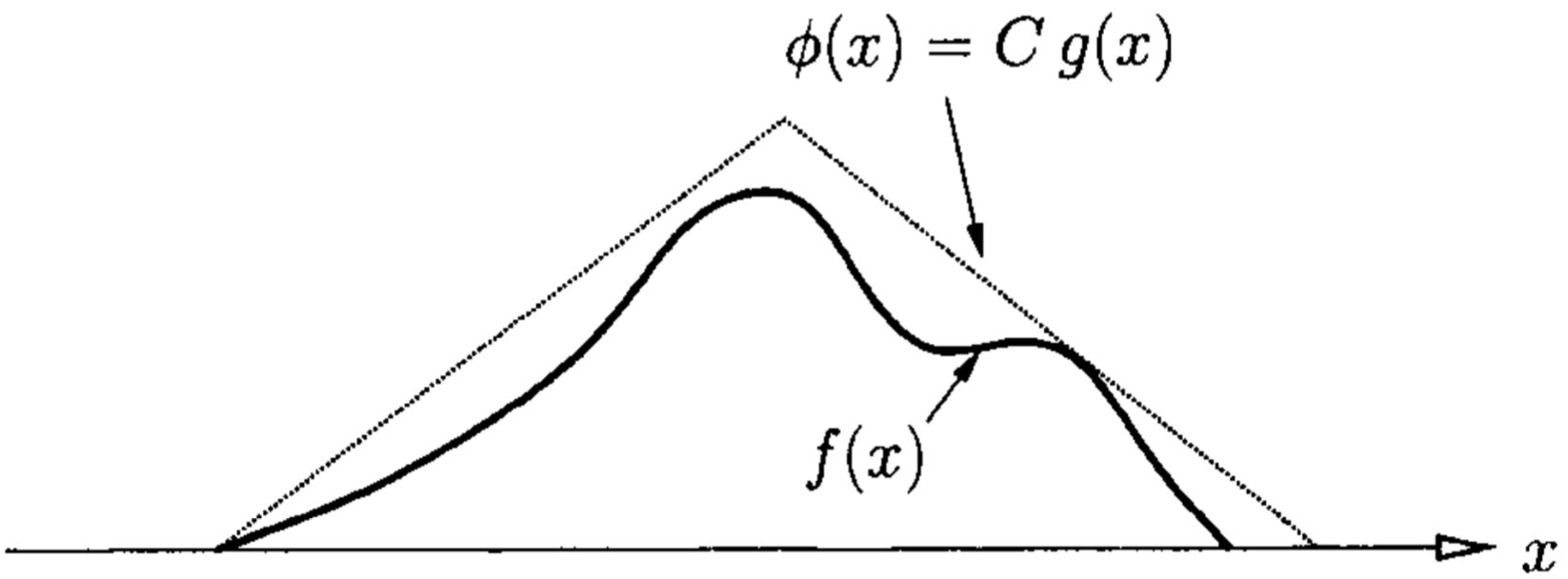
图(5):为了减少被拒绝的采样值的数量,使用一个接近而不是的函数来包围
取舍算法的缺点是其效率比较低,因为在接受一个随机数之前,大量的随机数被拒绝了。为了减少被拒绝的随机数的数量,实践上通常使用一个建议分布(proposal distribution)来逼近(称为目标分布)的分布,其中是一个简单的函数,它通常能够比较容易的(例如使用逆向变换算法)产生随机数常数用来保证能够完全覆盖,即:,如图(5)所示。所以上述的取舍算法可以写为:
- 产生随机数:。
- 产生随机数:。
- 如果, 则接受随机数:,否则返回第一步。
取舍方法不需要对函数执行归一化,只需要找到一个能够覆盖该分布函数的更简单的分布(建议分布)即可,例如对于:
(式3)
可以使用更简单的建议分布函数:
(式4)
注意,虽然对于一维的函数,取舍算��法需要产生两个随机数来做取舍判断,但是由于它减少单次采样的计算成本,因此它和逆向变换算法仍然具有可比性。
随机变量的变换
在前面讨论逆向变换算法的时候,我们介绍了一种技术,它可以将一个满足均分分布的随机变量转换为一个满足任意分布的随机变量。本节,我们将讨论与之相关的一个更一般的问题:即将满足任意分布的一个随机变量转换为满足另一个分布的随机变量。
假设随机变量的累积分布函数为,以及概率分布函数为,另一个随机变量是关于的连续单调递增函数,如图 (6)(a)所示,我们的目标是求出的累积分布函数的形式。

图(6):是一个连续函数,其中(a)是关于的单调递增函数,(b)是关于的单调递减函数
由于是单调递增的,因此有:
(式5)
所以的概率为:
(式6)
或者写成:
(式7)
和的概率分布函数之间的关系,可以通过对式(7)两边求微分得出:
(式8)
现在假设是关于的单调递减函数,如图(6)(b)所示,根据上面类似的推导过程,得到:
(式9)
所以随机变量和之间概率分布函数之间的关系为(通过组合式(8)和式(9)):
(式10)
上式反映出这样一个事实,即在区间的所有值被映射到在区间内,如图(7)所示。

图(7):在区间的所有值被映射到在区间内