4.5 方差缩减
通过前面的内容,我们已经熟悉了使用蒙特卡洛方法求积分的基本方法,这里再总结一遍,它基本上可以分为三个步骤:首先,使用前面讲述的一些采样方法(如逆向变换算法)从一个目标概率分布中采样产生一系列随机数;接着,将每个随机数代入式中求得每个样本的统计值;最后,求出这些统计值的平均值用来近似(估计)函数的积分。
由于蒙特卡洛方法是一个统计过程,因此方差始终存在,设计更有效的估计是蒙特卡洛方法研究中的主要领域,从蒙特卡洛方法诞生至今已出现非常多的方差缩减(variance reduction)的方法,但是由于蒙特卡洛方法在图形学中的运用往往都是要求计算不要太复杂,所以本节仅介绍少数几种计算机图形学中常用的方差缩减方法。
重要性采样
重要性采样(importance sampling)是蒙特卡洛方法中最基础也是非常重要和有效的方差缩减方法,它通过选择对一个与目标概率分布具有相似形状的分布函数进行采样来减少方差。直观上看,重要性采样试图在被积函数中贡献更高的区域放置更多的采样点,以体现这部分区域的重要性。
给定一个概率分布,以及从该分布采样得到的个随机数,根据蒙特卡洛方法,被积函数的积分可以通过以下式来进行估计:
(式1)
一个完美估计(perfect estimator)的方差应该为0,由此,相对理想的采样概率密度函数可以从下式推导出:
(式2)
因为是非零的,所以:
(式3)
如果我们使用这样的概率密度函数进行采样,其方差会被完美地消除,然而,这个理想的要求我们首先计算出的值,而这正是我们试图去求解的,因此找到这样理想的是完全不可能的。
不过,我们可以选择和被积函数具有相似形状的概率密度函数来减少方差,直观上理解,它使得每个样本值趋近于一个常数,也即是通过减少每个值的变化范围来减少方差,因为常数的方差为0。

图(1):重要性采样(右图)通过选择和被积函数具有相似形状的概率密度函数来进行采样,以减小统计方法导致的方差;此外,任意选择的分布(左图)可能比均匀分布(中图)具有更大的方差
图(1)展示了选择不同的概率密度函数对被积函数估计的差异,右边小图的重要性采样会比左图任意分布采样以及中间小图的均匀采样拥有更小的方差,此图也说明任意选择的采样(左边小图)可能比使用均匀分布(中间小图)的方差要大很多。所以从这里可以看出选择用于产生采样的概率密度函数的重要性,尽管蒙特卡洛方法本身没有限制对概率密度函数的选择,但是选择不好的概率密度函数会大大增加蒙特卡洛估计的方差。
复合重要性采样
在实际的情景中,计算机图形学中的被积函数通常是具有非常复杂,不正常的分布的,它们可能是不连续的,通常在少数区域拥有奇点(singularities)或者一些较大的值,所以很难找到一个简单的与其被积函数相似的分布用来进行重要性采样。
例如,考虑渲染中最普通的直接光源的计算,其公式如下:
(式4)
我们可能选择或来进行重要性采样,但是这两者都会产生糟糕的结果,因为一个不好的分布比均匀分布的方差要更大。考虑一个接近镜面的BRDF的表面被一个面积光照射的例子,如图(2)所示,这里面积光源的分布被用来作为采样函数,因为BRDF是几乎镜面的,所以除了沿镜面反射光方向,大部分光源上的采样对最终光照的贡献几乎为0,因此估计的方差会非常大;虽然这种情况下使用BRDF分布作为采样分布比较合适,但是对于被很小面积光源照射的漫反射或高光表面,使用BRDF作为采样分布仍然会导致很大的方差,此时我们应该尽可能地在光源上产生更多地采样点。
因此,我们通常需要使用更复杂的采样方式(而不是简单地从一个简单分布采样)以使估计具有更低的方差,这通常涉及根据被积函数的分布特征对其进行区域划分,然后在不同特征的区域上使用不同的分布函数进行采样,最后再将这些结果以某种方式进行混合。



图(2):对于一个被面积光照射的高光表面的直接光进行采样,这里有4个圆形面积光源,它们分别拥有不同的辐射照度及颜色,在四个圆形光源上面是一个聚光灯光源,所有的光源具有相同的辐射能量;下面是4个拥有不同粗糙度的高光矩形塑料(图片来自\cite{a:OptimallyCombiningSamplingTechniquesforMonteCarloRendering})
复合重要性采样(multiple importance sampling,MIS)就是这样一类采样方法,它非常简单而有效,它提供一个策略使得可以从多个不同的分布中采样,然后对这些不同的采样结果进行加权组合。根据原始论文[cite a:OptimallyCombiningSamplingTechniquesforMonteCarloRendering],复合重要性采样可以简单地分为以下几步:
- 首先,选择一系列的重要性分布,使得对于被积函数的每一个潜在值比较大的区域,在那个区域它能够被其中的一个单个重要性分布近似(形状相似),如图(3)所示。通常一个复杂的被积函数是多个不相关的简单分布的乘积的形式,所以这些重要性分布的最佳来源就是这些简单分布,使得可以正比于每个简单分布。
- 然后,从每个分布产生个随机数,这通常是根据某种策略基于和提前(在采样之前)计算而出。
- 最后,对每个分布的结果使用一个组合估计(combined estimator)进行加权组合以对积分进行估计。
复合重要性采样中的组合估计表达式如下:
(式5)
上式说明复合重要性采样是多个重要性采样的一个加权组合,它将整个空间按一定的形式划分,然后对每个划分的区域使用不同的采样技术,所以表示的就是这些不同采样技术的和;表示一种特定的采样技术的估计值,但是由于在每个区间内,每种技术只贡献其中一部分值,所以每种技术的估计结果被乘以一个系数,可以在每个处的值不一样,只要保证对于每个位置处满足就行,这样就能保证每个处的值被正确估计。

图(3):复合重要性采样对多个采样技术进行组合,即加权和,并可以根据每个区域内多个采样技术的贡献度来调整混合权重,使得联合估计结果能够充分发挥每个采样技术的优势
我们可以再解释一下这个加权系数的由来及原理,假设现有两个采样技术和如图(3)所示,两种采样技术单独的采样结果分别为和,它们都分别能够完全估计目标积分,但是各自的方差都很大。所以我们使用将两种采样技术进行组合,所以每个采样的区域是两个采样技术的加权和,为了尽可能发挥每个采样技术的优势,我们往往尽可能保证�在每个区域贡献更高的采样技术拥有更高的权重,这也正是后面平衡启发式的原理。
我们可以证明复合重要性采样的联合估计是无偏的:
(式6)
基于以上联合估计,我们可以选择使用不同的权重系数来混合多个采样分布,以尽可能减少估计的方差。
平衡启发式
考虑如下的权重系数函数:
(式7)
这里是每个采样分布对应的采样数量的比例,,所以,是一个固定的数值,它在采样之前确定。这个权重系数函数拥有一个属性,那就是采样值完全与无关,因为每个的采样值对于所有采样技术都是无关的,所以我们称这种策略为平衡启发式(balance heuristic)。
代入到式(5),我们得到标准的蒙特卡洛估计:
(式8)
这里:
(式9)
又称为联合采样分布(combined sample distribution),对于总数个采样,其中每个个独立的随机数分别从分布采样而得。
这就是平衡启发式的核心思想,也是一种很自然的组合多种采样技术的方式。我们使用一个单一的与完全无关的分布来表述这种组合方式。更进一步理解,是一个由每个组成的随机变量的分布,每个随机数的概率为。
除了平衡启发式,还存在一些其他的不同形式的混合系数函数,感兴趣的读者可以参考 [cite a:Safeandeffectiveimportancesampling,a:AdaptiveMultipleImportanceSampling,a:ANADAPTIVEPOPULATIONIMPORTANCESAMPLER,a:EfficientMultipleImportanceSamplingEstimators]等。
分层采样
重要性采样技术在被积函数更重要的区域放置更多的随机数来更好地逼近原始分布,然而它并不能消除由于随机数导致的丛聚(clumping),由于概率密度函数产生的随机数仅仅指示的是一个期望值,而不是一个绝对的数量。这些丛聚现象会导致估计的方差增大,因为它可能导致其他某些区域可能被忽略了。
与重要性采样调整采样函数的思路不同,针对上述问题,另一类常见的方差缩减的技术基于小心地设置采样随机数在被积函数区域的放置,其目标是使它们能够捕捉到被积函数的各部分重要信息(不至于由于随机数的丛聚导致某些部分被忽略),这类方法的结果是随机数不再是完全随机的,这类方法通常用作重要性采样等技术的一种补充。本节我们讨论分层采��样技术,而下一节讨论完全非随机的拟蒙特卡洛方法。
分层采样(stratified sampling)将被积函数的定义域划分成多个彼此不相交的子定义域,即满足:
(式10)
每个子定义域称为一个阶层(stratum),在每个阶层内,固定数量的个随机数分别从采样分布采样而得。在每个阶层内,其蒙特卡洛估计为:
(式11)
这里,是从采样分布中采样产生的第个随机数,因此整个被积函数的估计为:
(��式12)
这里表示每个阶层 ()占整个定义域空间的体积的比例,该估计的方差为:

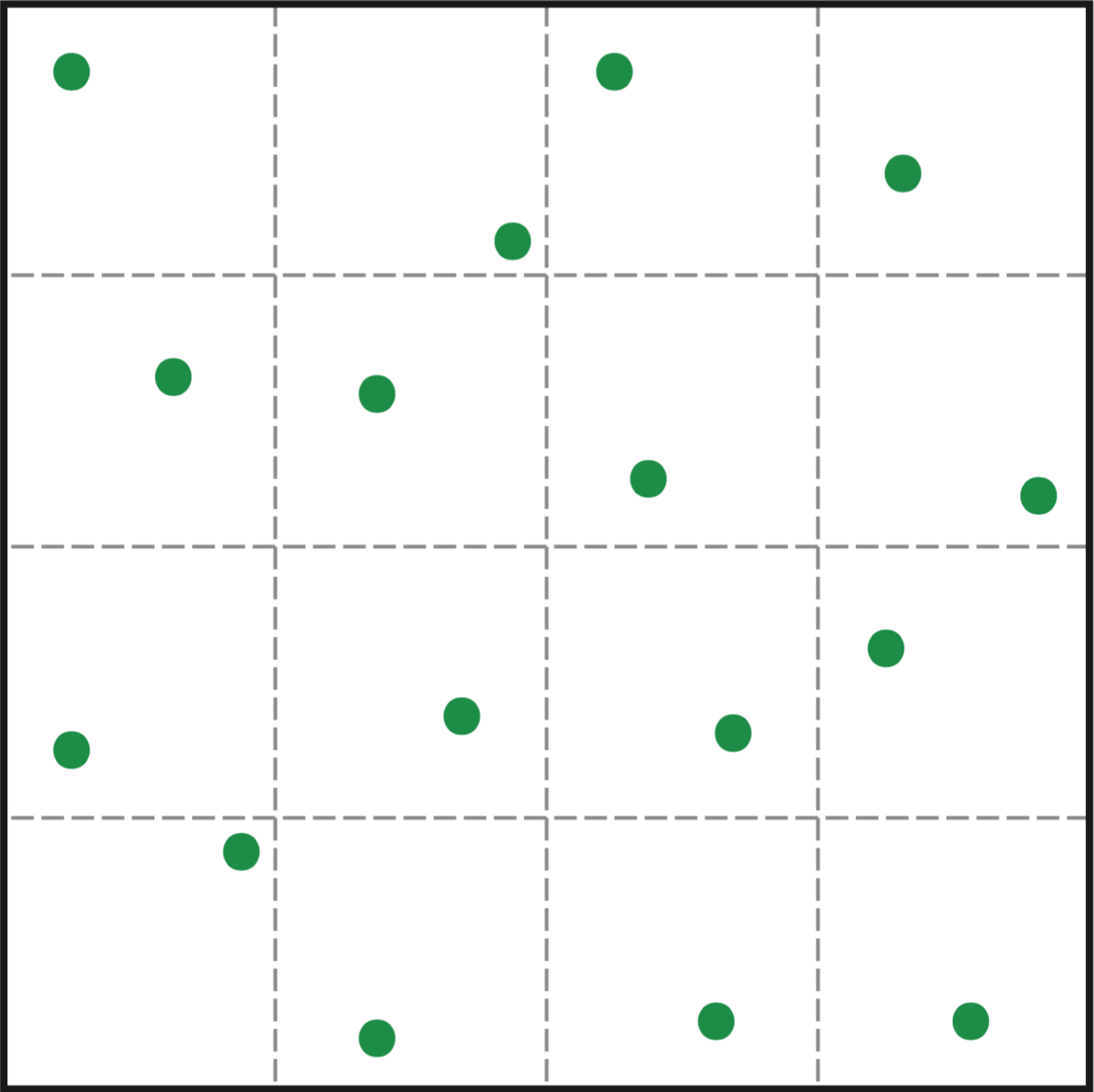
图(4):16个随机采样值和分层采样的比较,完全随机的采样(a)可能会导致丛聚,丛聚可能使得被积函数其他区域采样不足从而增加估计的方差
(式13)
这里表示在阶层内的估计的方差。
为了与其他非分层采样方法进行比较,假设,为估计全部使用的样本,上式可以简化为:
(式14)
另一方面,非分层采样估计的方差可以表示为(感兴趣的读者可以参见[cite a:RobustMonteCarloMethodsforLightTransportSimulation]第51页的推导过程):
(式15)
其中,表示阶层内的平均值(或者说期望),表示整个定义域内的期望,因为右边的和总是非负的,所以分层采样永远不会增加估计的方差,如图(4)所示。
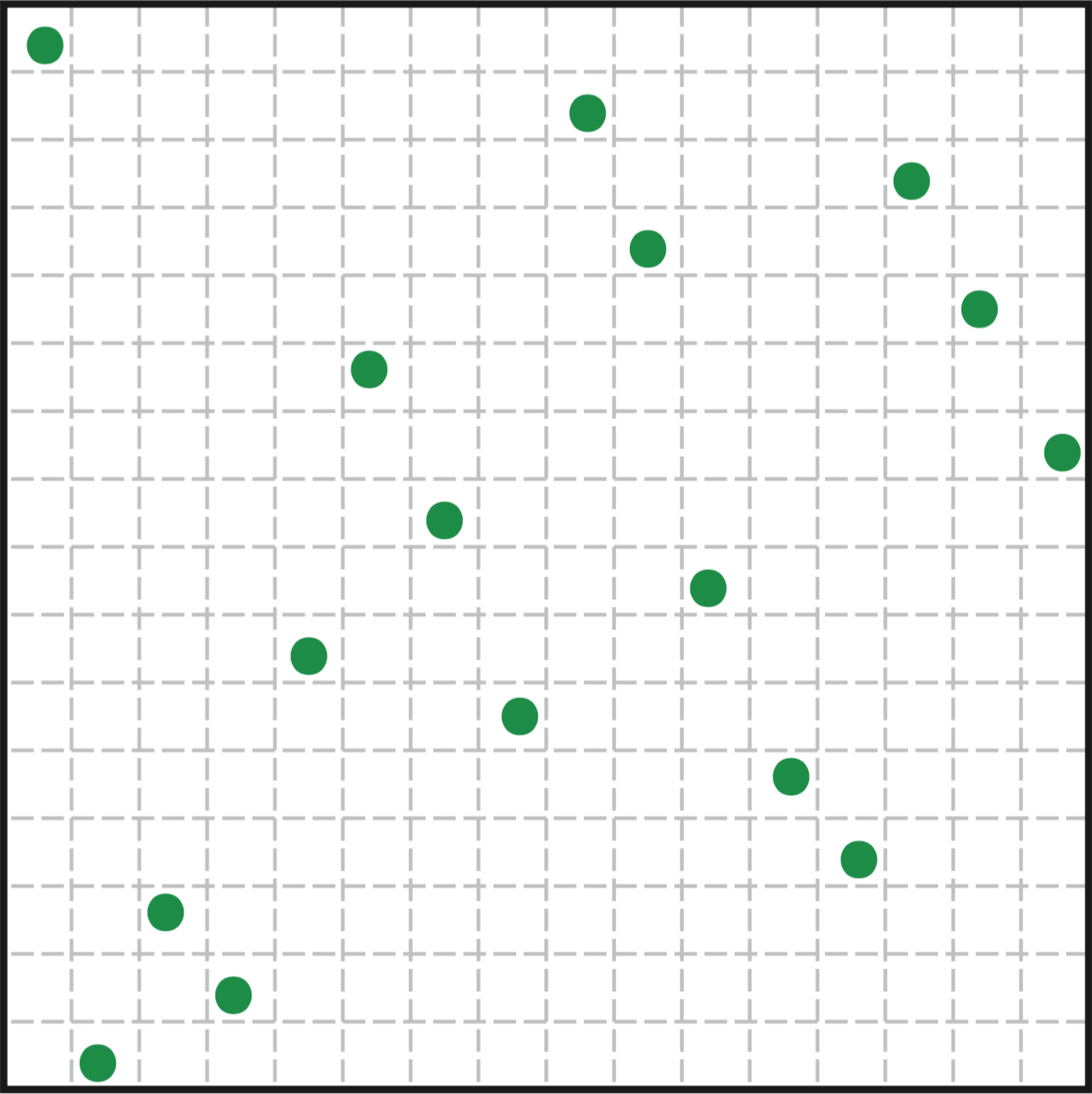
图(5):在2维的空间中,$N$-rooks算法保证每个行或列不会放置超过两个随机数
分层采样方法的主要缺点是对高维积分是无效的,一般地说,维的定义域空间可能需要个阶层划分,针对这个问题,一些变体采样方法被提出,例如-rooks算法保持总的采样数量是固定的,即其与定义域的维度无关。例如,考虑一个2维的函数,使用每个阶层一个采样点的分层采样,一共需要个阶层划分;-rooks算法则将这个采样点均匀地分配在各个阶层空间,在这个例子中就是保证每个行和列的组合只包含一个采样点,如图(5)所示,关于-rooks算法,更详细的描述参见Shirley的博士论文[cite a:PhysicallyBasedLightingCalculationsForComputerGraphics]。
沿着这种改变随机性的思路,拟蒙特卡洛方法则完全去掉随机性,使得随机数完全按照某种固定序列均匀分布来避免丛聚,我们将在下一节讨论拟蒙特卡洛方法。
拟蒙特卡洛方法
虽然大数定律证明,当采样数量趋近于无穷的时候,蒙特卡洛估计趋近于期望值的概率为1,但是传统蒙特卡洛方法的收敛速度非常慢,其标准差,即增加4倍的采样数量才能换来2倍的精确度提升。
在上一节中已经证明,分层采样减少了蒙特卡洛估计的方差,这主要是由于阶层的划分减少了随机数导致的丛聚,那么更进一步,我们可不可以采用完全均匀的采样来代替随机分布,使得蒙特卡洛估计的方差进一步降低,收敛速度更快呢?
重新思考蒙特卡洛方法,其随机变量的独立性是指其对应的随机事件之间是不相关的,但是蒙特卡洛方法并没有限制随机数产生的方式,��它只要求采样的随机数满足对应的分布。传统的采样方式是使用电脑的伪随机数来进行的,这种随机的特征导致每个随机数并不知道其他随机数的任何信息,所以其分布可能出现丛聚,减慢了收敛速度。所以,理论上如果我们使用确定性(非随机)的方法来产生均匀地分布,那么蒙特卡洛方法的模拟过程不会受到影响,并且收敛速度可以加快。
拟蒙特卡洛方法(Quasi-Monte Carlo method)就是这样一种方法,它和传统蒙特卡洛方法的唯一不同仅在于随机数产生的方式,拟蒙特卡洛方法使用低差异(low-discrepancy)序列,这些序列是通过数论方法产生的高度均匀的拟随机数序列,例如霍尔顿序列,索波尔序列等。本节我们将首先讨论均匀性以及拟蒙特卡洛方法的方差,然后介绍几种常见的低差异序列。
设和是区间内的点,对于的每个分量都满足,则可以表示一些点组成的一个盒子区域,对于每个分量这些点满足,我们用表示这个d-维盒子的体积。
设是上的随机数,为了分析一个序列的均匀性(uniformity)对收敛速度的影响,我们需要一个数值方法来度量一个序列有多么均匀,这个度量称为差异(discrepancy),差异有许多形式,其中的一种称为星差异(star discrepancy),它的定义如下:
(式16)
表示的是盒子内的采样占总采样数量的比例,所以星偏差(偏差的一般形式定义中盒子中的和可以取任意值,而不是一个固定在原点的盒子。}表示的是在所有盒子中,盒子体积与其盒子内点所占总数比例的差的绝对值的最大值。图(6)展示了这种偏离度的概念,它包含一个固定在原点的盒子以及一个的序列,盒子里面有4个点,所以,而盒子的体积为,所以其差为,星偏差是取所有盒子的最大值。

图(6):图为在一个单位正方形内的20个点组成的序列,以及一个固定在原点的盒子,,盒子的体积为0.15,占据的点的比例为。
有了序列的偏差度的数值定义,我们可以用它来分析序列的均匀性对估计错误程度的影响。拟蒙特卡洛估计的错误被其使用的序列的偏差限定在一个有界区间内,更精确地讲,Koksma–Hlawka不等式(The Koksma–Hlawka inequality)声明拟蒙特卡洛估计的错误(这里的错误定义和方差是有一点区别的,估计值和期望值之差的绝对值才是估计错误的真实形式,而方差的定义为了避免绝对值带来的麻烦而使用错误平方的期望形式表示。):
(式17)
被限定在区域:
(式18)
之内。这里的函数为被积函数的Hardy-Krause方差(Hardy-Krause variation),该不等式可以用于展示拟蒙特卡洛估计的错误边界为,而传统蒙特卡洛估计的错误为。虽然我们只能声明拟蒙特卡洛估计错误的上边界(upper bound)值,但实践上拟蒙特卡洛方法的收敛速度要比理论上快得多,因此一般情况拟蒙特卡洛方法比传统的蒙特卡洛方法的收敛速度要快;此外,从该表达式也可以看出拟蒙特卡洛估计的维数越小,其估计错误越小,收敛速度越快,
低差异序列
产生低差异序列的方法和伪随机数序列的方法是完全不同的。产生多维伪随机数序列的间接方法是首先由伪随机数发生器(如系统中的random(u)函数)产生一维随机数序列,然后根据概率论定理,用间接方法(如逆向变换算法,取舍算法等)将一维伪随机数序列转换为多维伪随机数序列;然而拟随机数不是随机的,而是确定的,没有概率统计特性,因此不能像产生多维伪随机数那样的方法工作。
因此我们使用直接方法产生多维拟随机数序列。直接方法即是数论方法,数论方法是基于数论中的一致分布理论,利用数论中关于整数,素数,同余式等知识产生多维拟随机数序列。数论当中有许多方法用于产生低差异序列(low-discrepancy sequence)的方法,本节我们仅讨论比较常用的几种利用倒根函数实现的低差异序列。
倒根函数
任何一个自然数可以展开为以为底的正幂次的表达式,即是用进制表示自然数,其中称为基(radix),其展开式为:
(式19)
其中,为数字展开式的系数,为数字展开式的项数,决定了在进制下的位数,它允许展开个自然数,例如数字123用10进制表示为。如果我们将展开系数看成一个维的向量,则该展开式将一个自然数序列转换成了一个多维的向量序列。
有了这个多维向量序列,为了将它转换为空间的向量序列,首先需要将该序列转换为进制的小数形式,这就需要用到倒根函数(radical(此处radical实际上是取名词radix的形容词形式,因此理解为"根的,基的"意思,和"base"的意思是一致的,因此倒根函数指的是对基进行反向映射,由进制映射回10进制。) inverse function),倒根函数表示将该序列转换为以为底的负幂次的表达式,即是进制的小数形式,其定义如下:
(式20)
其中,是一个生成矩阵(generator matrix),生成矩阵通常和底数的选择有关,每个低差异序列算法中的不同点就在于底数和生成矩阵的选择。
有了进制小数形式的多维拟随机向量,最后一步直接将该向量转换为10进制即可,以上的过程就将自然数一共个数转换为个空间上的向量序列,即是我们最终需要的拟随机数序列。以下我们简单介绍两种基于倒根函数生成的低差异序列。
科普特序列
科普特序列(van der Corput sequence)是一维的拟随机数序列,其一维底数可取任一素数,为单位矩阵。例如以底数2为例,图(7)列出了16个拟随机数组成的特普特序列,由于为单位矩阵,所以正幂次的2进制形式在转换为负幂次的2进制形式的时候,相当于将每个展开系数的顺序反转,如图(7)中的第二,三列所示。

图(7):16个拟随机数的一维科普特序列,其中底数为2,为单位矩阵,科普特序列主要就是靠反转二进制形式的各个位的顺序来获得。
霍尔顿序列}
另一个常用的低差异序列是霍尔顿序列(Halton sequence),霍尔顿序列是科普特序列扩展到高维的一般形式,即��是霍尔顿序列的生成矩阵也是单位矩阵,但是霍尔顿序列的底数选择方式不一样,一维的霍尔顿序列就是底数为的科普特序列。
霍尔顿序列的每维有不同的底数,霍尔顿序列第维的底数是第个素数,即维数取值,对应维数的霍尔顿序列底数取值为,根据数论中的判别素数的相关方法可以得到自然数素数表。


图(8):256个伪随机数序列和开头256个Halton(2,3)序列中随机数的均匀性比较(图片来自Wikipedia)
由于数字展开式,而霍尔顿序列的底数随维数增加而增加,所以当维数越高,底数就越大,系数个数就越多,计算循环时间越长。此外,由于高维使用的底数是比较大的素数,循环会很长,出现一些空隙结构,所以霍尔顿序列的均匀性在10维以上逐渐变坏,出现丛聚现象,20维以上丛聚就比较明显了,所以并不适合高维的拟随机数序列。
有很多低差异序列用于改善高维霍尔顿序列的退化现象,这里不再详述,相比这些序列,霍尔顿序列的而优势在于生成矩阵为单位矩阵,而其他低差异序列往往有着非常复杂的生成矩阵,计算复杂度大大增加,所以在低维情况下霍尔顿序列几乎是最好的选择。